
Objectif 🎯
Dans la section précédente, nous sommes arrivés à une infra physique montée avec un kube joignable, mais en statut node.kubernetes.io/not-ready et node.cloudprovider.kubernetes.io/uninitialized. En effet, il nous reste 2 composants essentiels à installer pour que notre cluster soit pleinement fonctionnel :
- Un CNI (Container Network Interface) pour gérer le réseau des pods et services. Nous utiliserons cilium qui est un CNI moderne, performant et riche en fonctionnalités.
- Un CCM (Cloud Controller Manager) pour que Kubernetes puisse interagir avec l’infrastructure Hetzner Cloud et récupérer les metadata pour les nodes. Nous utiliserons hcloud-cloud-controller-manager.
On finalisera l’architecture réseau avec cert-manager pour la gestion des certificats TLS.
Initialisation
L’architecture du projet Terraform cible est le suivant :
├── clusters│ └── dev-hcloud│ └── ...│ └── dev-kube│ ├── fnox.toml│ ├── flux.tf│ ├── locals.tf│ ├── module-database.tf│ ├── module-delivery.tf│ ├── module-ingress.tf│ ├── module-monitoring.tf│ ├── module-network.tf│ ├── module-storage.tf│ ├── terraform.tf│ └── variables.tf├── modules └── hcloud └── ... └── kube ├── database │ ├── cnpg.tf │ ├── dragonfly.tf │ ├── longhorn.tf │ ├── pgadmin.tf │ ├── talos.tf │ └── variables.tf ├── delivery │ ├── flux.tf │ ├── kustomization.yaml │ ├── providers.tf │ └── variables.tf ├── ingress │ ├── cert-manager.tf │ ├── crowdsec.tf │ ├── haproxy.tf │ ├── traefik.tf │ └── variables.tf ├── monitoring │ ├── alloy.tf │ ├── grafana.tf │ ├── loki.tf │ ├── prometheus.tf │ ├── tempo.tf │ └── variables.tf ├── network │ ├── cert-manager.tf │ ├── cilium.tf │ ├── hccm.tf │ ├── metrics-server.tf │ └── variables.tf └── storage ├── cnpg.tf ├── longhorn.tf └── variables.tfIl sera donc décomposé en 5 grands modules :
module-networkpour l’architecture réseau (CNI, CCM, certificats, service mesh)module-storagepour l’architecture de stockage (CSI, opérateurs de bases de données et backup)module-ingresspour la construction de l’ingress public et privé, ainsi que WAF et certificats TLSmodule-databasepour la création de clusters de base de données et définition des backupsmodule-monitoringpour la supervision des métriques, logs et tracing
State
Le plus simple est de stocker l’état Terraform dédié au kube dans le même backend S3, juste à côté du state dédié à la partie hcloud, sous terraform/kube.tfstate. On en profite pour définir les providers kubernetes et helm en leur indiquant la config d’accès kube.
backend "s3" { endpoints = { s3 = "https://s3.gra.io.cloud.ovh.net" } skip_credentials_validation = true skip_region_validation = true skip_requesting_account_id = true skip_s3_checksum = true region = "gra" bucket = "ohmytalos-dev" key = "terraform/kube.tfstate" encrypt = true }}
provider "kubernetes" { config_path = "~/.kube/config"}
provider "helm" { kubernetes = { config_path = "~/.kube/config" }}Warning (kubernetes secret)
Le state étant inextricablement lié au cluster cible, vous pourriez éventuellement vous dire que l’on pourrait le stocker dans un secret kubernetes en utilisant le backend kubernetes comme suit :
terraform { backend "kubernetes" { config_path = "~/.kube/config" secret_suffix = "talos" }}
//...En soi cela peut fonctionner, mais ce n’est clairement pas la bonne façon de procéder, en raison du risque de fuite du state accru (nécessite la mise en place d’RBAC), risque de dépendance circulaire.
Cilium et HCCM
On peut maintenant passer au module module-network pour installer Cilium et le cloud controller manager.
locals { cluster_name = "ohmytalos-dev" internal_domain = "dev.ohmytalos.com"}module "kube_network" { source = "../../modules/kube/network"
pod_ipv4_cidr = "10.42.0.0/16" internal_domain = local.internal_domain
hcloud_token = var.hcloud_token hcloud_network = local.cluster_name}Explanation
Cilium aura besoin de connaître le CIDR utilisé pour les pods pour la création dynamique des routes sur le network hcloud natif.
Nous utiliserons dev.ohmytalos.com comme domaine interne pour les services accessibles uniquement via le réseau privé Tailnet. La génération des certificats TLS, nécessairement via challenge DNS-01, sera gérée par cert-manager plus tard.
Côté hccm, dans le cadre de la création des routes, ce dernier a besoin de connaître le nom du réseau Hetzner Cloud à utiliser, nommé selon le nom du cluster. Un token d’API Hetzner Cloud en écriture est évidemment indispensable pour créer les routes ainsi que le load-balancer dynamiquement plus tard via Traefik.
variable "hcloud_token" { type = string sensitive = true}fnox set TF_VAR_hcloud_token "xxxxxxxxxxxxxxxxxxxxx" --provider agevariable "pod_ipv4_cidr" { description = "The CIDR for the pod network" type = string}
variable "internal_domain" { description = "The internal domain name to use for the private network" type = string}
variable "hcloud_token" { description = "The Hetzner Cloud API token" type = string sensitive = true}
variable "hcloud_network" { description = "The ID or name of the main hetzner network of this cluster" type = string}resource "helm_release" "cilium" { repository = "https://helm.cilium.io" chart = "cilium" version = "1.19.3"
name = "cilium" namespace = "kube-system"
max_history = 2
set = [ { name = "ipam.mode" value = "kubernetes" }, { name = "routingMode" value = "native" }, { name = "ipv4NativeRoutingCIDR" value = var.pod_ipv4_cidr }, { name = "kubeProxyReplacement" value = "true" }, { name = "loadBalancer.acceleration" value = "best-effort" }, { name = "encryption.enabled" value = "true" }, { name = "encryption.type" value = "wireguard" }, { name = "securityContext.capabilities.ciliumAgent" value = "{CHOWN,KILL,NET_ADMIN,NET_RAW,IPC_LOCK,SYS_ADMIN,SYS_RESOURCE,DAC_OVERRIDE,FOWNER,SETGID,SETUID}" }, { name = "securityContext.capabilities.cleanCiliumState" value = "{NET_ADMIN,SYS_ADMIN,SYS_RESOURCE}" }, { name = "cgroup.autoMount.enabled" value = "false" }, { name = "cgroup.hostRoot" value = "/sys/fs/cgroup" }, { name = "k8sServiceHost" value = "127.0.0.1" }, { name = "k8sServicePort" value = 7445 }, { name = "hubble.relay.enabled" value = "true" }, { name = "hubble.ui.enabled" value = "true" }, { name = "envoy.enabled" value = "false" }, { name = "prometheus.enabled" value = "true" }, { name = "prometheus.serviceMonitor.enabled" value = "true" }, { name = "dashboards.enabled" value = "true" }, { name = "operator.prometheus.enabled" value = "true" }, { name = "operator.prometheus.serviceMonitor.enabled" value = "true" }, { name = "operator.dashboards.enabled" value = "true" }, { name = "hubble.relay.prometheus.enabled" value = "true" }, { name = "hubble.relay.prometheus.serviceMonitor.enabled" value = "true" }, { name = "hubble.metrics.serviceMonitor.enabled" value = "true" }, { name = "hubble.metrics.dashboards.enabled" value = "true" } ]
set_list = [ { name = "hubble.metrics.enabled" value = [ "dns:query;ignoreAAAA", "drop", "tcp", "flow", "icmp", "http" ] } ]}
resource "kubernetes_manifest" "traefik_ingress_route_cilium" { manifest = { apiVersion = "traefik.io/v1alpha1" kind = "IngressRoute" metadata = { name = "hubble-ui" namespace = "kube-system" } spec = { entryPoints = ["internal"] routes = [ { match = "Host(`hubble.${var.internal_domain}`)" kind = "Rule" middlewares = [ { name = "internal-basic-auth" namespace = "traefik" } ] services = [ { name = "hubble-ui" port = "http" } ] } ] } }}Explanation
Pour les besoins d’intégration complète au hccm, nous utilisons l’adressage IP en mode kubernetes et activons le routing natif. On remplace le kube-proxy péalablement désactivé au niveau de la config Talos par celui de Cilium pour bénéficier de meilleures performances réseau.
Le chiffrement inter-pods est activée via Wireguard pour sécuriser les communications entre pods sur les nœuds. Nous avons également besoin d’ajouter plusieurs capacités au cilium-agent pour qu’il puisse fonctionner correctement sur Talos, notamment SYS_ADMIN pour la gestion des interfaces réseau.
On active Hubble pour avoir une interface web d’observabilité réseau temps réel. Nous n’utiliserons pas Envoy, qui est un proxy L7, pour ne pas abuser de la mémoire vive sur nos nœuds avec un autre DaemonSet. Si vous estimer avoir besoin de faire du network policy L7 (HTTP), n’hésitez pas à l’activer.
On active l’ensemble des ServiceMonitor et dashboards Grafana pour Cilium et Hubble, qui seront automatiquement détectés par Prometheus et Grafana plus tard.
Nous créons également un IngressRoute Traefik pour exposer l’interface web de Hubble en interne, protégée par un middleware BasicAuth que nous définirons plus tard dans le module module-ingress. Nous ne pourrons pas y accéder dans un 1er temps sauf via kpf -n kube-system svc/hubble-ui 8000:http.
resource "kubernetes_secret_v1" "hcloud" { metadata { name = "hcloud" namespace = "kube-system" } data = { token = var.hcloud_token, network = var.hcloud_network }}
resource "helm_release" "hccm" { repository = "https://charts.hetzner.cloud" chart = "hcloud-cloud-controller-manager" version = "1.30.1"
name = "hccm" namespace = "kube-system" max_history = 2
set = [ { name = "networking.enabled" value = "true" }, { name = "networking.clusterCIDR" value = var.pod_ipv4_cidr }, { name = "monitoring.enabled" value = "true" }, { name = "monitoring.podMonitor.enabled" value = "true" } ]
depends_on = [ kubernetes_secret_v1.hcloud, helm_release.cilium ]}Explanation
Activer la gestion du réseau hcloud. L’installation du hccm doit impérativement se faire après l’installation de Cilium, car l’opérateur ne pourrait pas tourner sans CNI. Nous utilisons un kubernetes_secret pour passer le token d’API et le nom du réseau au chart Helm.
Note : On indiquera max_history = 2 sur tous nos charts Helm pour ne pas garder inutilement un tas d’historiques de versions dans le cluster.
Les versions de chart helm seront indiquées en dur, cela ne posera aucun problème à des outils tel que renovate pour maintenir vos versions à jour.
Note (Historiques Helm et versions)
On indiquera max_history = 2 sur tous nos charts Helm pour ne pas garder inutilement un tas d’historiques de versions dans le cluster.
Les versions de chart helm seront indiquées en dur, cela ne posera aucun problème à des outils tel que renovate pour maintenir vos versions à jour.
Le coeur de la config réseau est maintenant en place. Comme précédemment sur le projet hcloud, préparer vos secrets pour l’accès au state :
fnox set AWS_ACCESS_KEY "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set AWS_SECRET_KEY "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set AWS_SSE_CUSTOMER_KEY "xxxxxxxxxxxxxxxxxxxxx" --provider ageEnfin lancer la commande terraform init puis terraform apply dans le dossier clusters/dev-kube pour installer notre duo Cilium et HCCM.
Si tout se passe bien, les noeuds devraient rapidement passer en statut Ready et en statut cloud initialisé. Vous pouvez vérifier cela avec les commandes suivantes (j’utiliserais dorénavant les alias fournis par oh-my-zsh pour kubectl) :
kgnokdno okami-dev-control-plane-nbg1Vous devriez apercevoir cette ligne spécifique indiquant que le CCM est bien actif :
# ...ProviderID: hcloud://xxxxxxxxx # où xxxxxxxxx est l'ID du serveur Hetzner CloudEtant donné l’usage du mode natif pour Cilium, vous devriez également voir les routes dynamiques créées sur le réseau Hetzner Cloud, une correspondant à chaque nœud, et permettant la communication entre les pods à travers les différents nœuds via le réseau “physique” Hetzner Cloud :
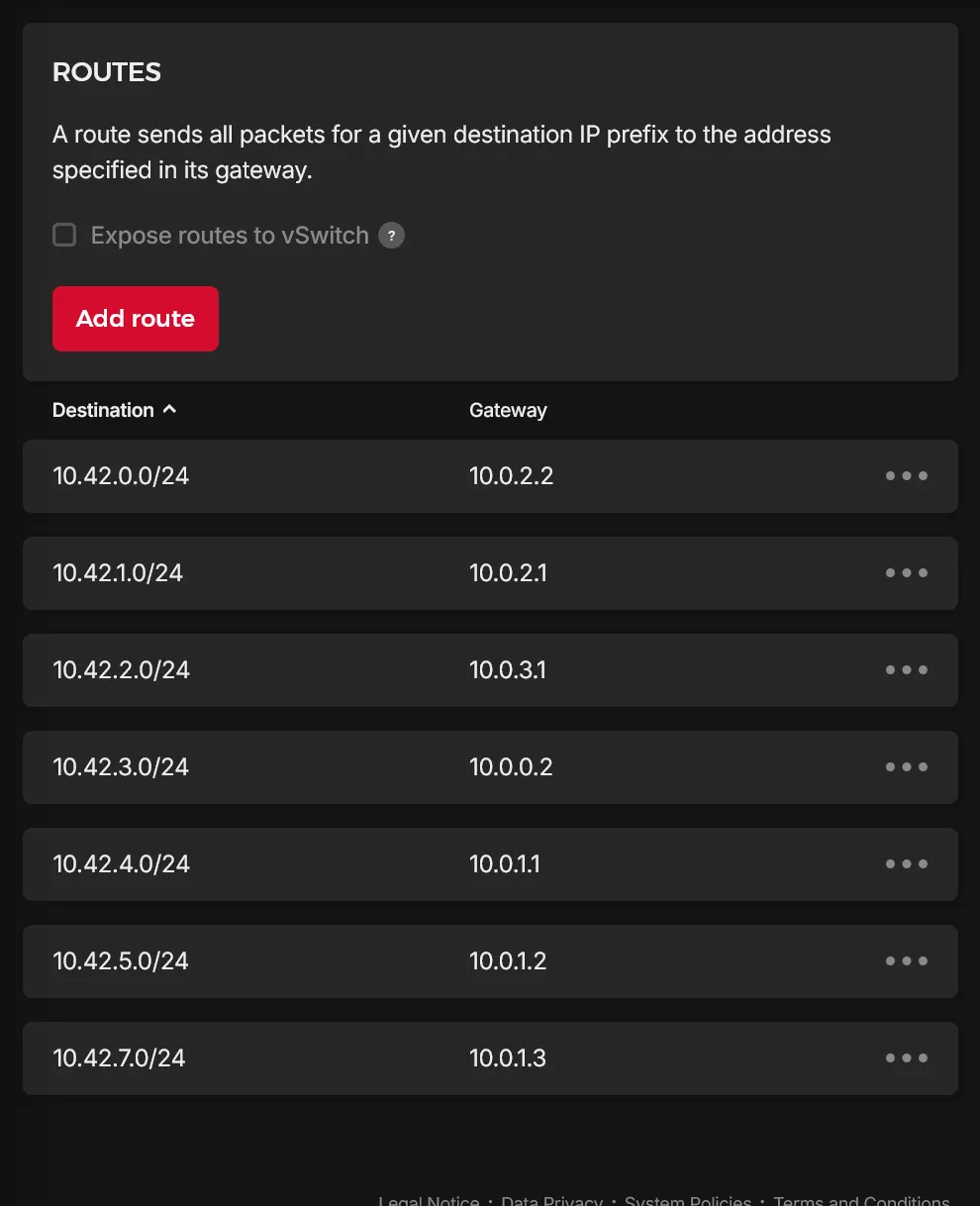
Vous pouvez maintenant lancer talosctl -n 10.0.0.2 health pour vérifier l’état de santé global du cluster. Tout devrait répondre correctement. Utiliser cilium status pour vérifier que Cilium est bien opérationnel.
Notre cluster kube est dorénavant pleinement fonctionnel et utilisable.
Metrics Server
Nous allons installer metrics-server pour bénéficier de certaines métriques propres à l’usage courant de Kubernetes.
resource "helm_release" "metrics_server" { repository = "https://kubernetes-sigs.github.io/metrics-server" chart = "metrics-server" version = "3.13.0"
name = "metrics-server" namespace = "kube-system" max_history = 2
set = [ { name = "metrics.enabled" value = "true" }, { name = "serviceMonitor.enabled" value = "true" } ]
depends_on = [ helm_release.hccm ]}Ceci vous permettra notamment l’utilisation de k top nodes et k top pods pour voir l’usage CPU/mémoire de vos nœuds et pods. Il est aussi requis les fonctionnalités d’autoscaling qui ne seront pas l’objet de ce guide.
Cert-Manager
Dernière étape réseau, l’installation de cert-manager pour la gestion des certificats TLS. Nous en aurons besoin pour les certificats internes et externes.
resource "kubernetes_namespace_v1" "cert_manager" { metadata { name = "cert-manager" }
depends_on = [helm_release.hccm]}
resource "helm_release" "cert_manager" { repository = "https://charts.jetstack.io" chart = "cert-manager" version = "v1.20.2"
name = "cert-manager" namespace = kubernetes_namespace_v1.cert_manager.metadata[0].name max_history = 2
set = [ { name = "crds.enabled" value = "true" }, { name = "prometheus.servicemonitor.enabled" value = "true" } ]}Conclusion
Les principaux composants réseau sont maintenant en place. Assurez-vous d’avoir un terraform apply propre avant de continuer, suite à la prochaine section pour l’installation de l’infra de stockage.