
Objectif 🎯
À la fin de la section précédente, nous sommes arrivés à un kube pleinement opérationnel. Il nous reste cependant à mettre en place une réelle solution de stockage distribuée. Il existe les solutions simples telles que local-path-provisioner , nfs-subdir-external-provisioner, ou encore hetznercloud/csi-driver. Mais ce ne sont pas des solutions réellement viables en production pour des raisons évidentes telles que la résilience, la haute disponibilité, la sauvegarde/restauration, etc.
Les 3 solutions de stockage distribuées les plus connues sont :
Dans le cadre de ce guide, nous partirons sur Longhorn, qui me semble le plus équilibré au regard des capacités en ressources des VPS Hetzner et de la taille de notre cluster.
Longhorn
locals { cluster_name = "ohmytalos-dev" internal_domain = "dev.ohmytalos.com" s3_endpoint = "https://s3.gra.io.cloud.ovh.net" s3_region = "gra"}module "kube_storage" { source = "../../modules/kube/storage"
internal_domain = local.internal_domain
longhorn_crypto_key_value = var.longhorn_crypto_key longhorn_backup_s3_endpoint = "https://${local.s3_endpoint}" longhorn_backup_s3_access_key = var.longhorn_backup_s3_username longhorn_backup_s3_secret_key = var.longhorn_backup_s3_password longhorn_backup_s3_region = local.s3_region longhorn_backup_s3_bucket = local.cluster_name longhorn_default_local_replica_count = 2 longhorn_default_volume_replica_count = 2 longhorn_default_taint_tolerations = [ "node-role.kubernetes.io/storage:NoSchedule" ]}Explanation
Bien que tous les volumes physiques de base soient déjà chiffrés au niveau OS, nous utiliserons également des volumes chiffrés côté longhorn. Cela ne coûte pas bien plus cher en ressource et permet de notamment de chiffrer les backups, ces derniers étant effectués en mode block.
Configurer les accès S3 pour le stockage des backups. Nous utiliserons OVH, mais n’importe quel fournisseur compatible S3 fera l’affaire. Prenez le même bucket déjà dédié à ce cluster ohmytalos-dev.
La définition du nombre de réplicas selon le niveau de résilience des données est importante. Dans notre configuration actuelle du cluster, nous définissons :
- 2 réplicas par défaut pour les volumes locaux, qui vivent à travers l’ensemble du cluster. Mettre à 3 si besoin pour plus de résilience.
- 2 réplicas pour les volumes externes, requis car nous sommes limités à 2 disques externes (un dans chaque nœud) dans la définition du pool de storage de l’étape 2.
La définition des teintes est importantes pour s’assurer que les composants longhorn (manager et engine) soient bien programmés sur tous les nœuds workers.
// ...
variable "longhorn_backup_s3_username" { type = string}
variable "longhorn_backup_s3_password" { type = string sensitive = true}
variable "longhorn_crypto_key" { type = string sensitive = true}fnox set TF_VAR_longhorn_backup_s3_username "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_longhorn_backup_s3_password "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_longhorn_crypto_key "xxxxxxxxxxxxxxxxxxxxx" --provider agevariable "internal_domain" { description = "The internal domain name to use for the private network" type = string}
variable "longhorn_backup_s3_endpoint" { description = "The endpoint of the S3 compatible storage" type = string}
variable "longhorn_backup_s3_access_key" { description = "The access key for the S3 compatible storage" type = string}
variable "longhorn_backup_s3_secret_key" { description = "The secret key for the S3 compatible storage" type = string sensitive = true}
variable "longhorn_backup_s3_region" { description = "The region of the S3 compatible storage" type = string}
variable "longhorn_backup_s3_bucket" { description = "The bucket of the S3 compatible storage" type = string}
variable "longhorn_default_local_replica_count" { description = "The default replica count for the local longhorn storage class and UI" type = number default = 3}
variable "longhorn_default_volume_replica_count" { description = "The default replica count for the volume longhorn storage class and UI" type = number default = 3}
variable "longhorn_default_taint_tolerations" { description = "The default taint tolerations for the longhorn components" type = list(string)}
variable "longhorn_crypto_key_value" { description = "The encryption key value for Longhorn volumes" type = string sensitive = true}resource "kubernetes_namespace_v1" "longhorn" { metadata { name = "longhorn-system" labels = { "pod-security.kubernetes.io/enforce" = "privileged" } }}
resource "kubernetes_secret_v1" "backup_target_credential" { metadata { name = "backup-target-credential" namespace = kubernetes_namespace_v1.longhorn.metadata[0].name } data = { AWS_ENDPOINTS = var.longhorn_backup_s3_endpoint AWS_ACCESS_KEY_ID = var.longhorn_backup_s3_access_key AWS_SECRET_ACCESS_KEY = var.longhorn_backup_s3_secret_key AWS_REGION = var.longhorn_backup_s3_region } lifecycle { ignore_changes = [metadata[0].annotations] }}
resource "kubernetes_secret_v1" "longhorn_crypto" { metadata { name = "longhorn-crypto" namespace = kubernetes_namespace_v1.longhorn.metadata[0].name } data = { CRYPTO_KEY_VALUE : var.longhorn_crypto_key_value CRYPTO_KEY_PROVIDER : "secret" CRYPTO_KEY_CIPHER : "aes-xts-plain64" CRYPTO_KEY_HASH : "sha256" CRYPTO_KEY_SIZE : "256" CRYPTO_PBKDF : "argon2i" }}
resource "helm_release" "longhorn" { repository = "https://charts.longhorn.io" chart = "longhorn" version = "1.11.1"
name = "longhorn" namespace = kubernetes_namespace_v1.longhorn.metadata[0].name max_history = 2
set = concat( [ { name = "metrics.serviceMonitor.enabled" value = "true" }, { name = "defaultBackupStore.backupTargetCredentialSecret" value = kubernetes_secret_v1.backup_target_credential.metadata[0].name }, { name = "defaultBackupStore.backupTarget" value = "s3://${var.longhorn_backup_s3_bucket}@${var.longhorn_backup_s3_region}/longhorn/" }, { name = "defaultSettings.createDefaultDiskLabeledNodes" value = "true" }, { name = "defaultSettings.defaultLonghornStaticStorageClass" value = kubernetes_storage_class_v1.longhorn_crypto.metadata[0].name }, { name = "defaultSettings.taintToleration" value = join(";", var.longhorn_default_taint_tolerations) } ], [ for i, toleration in var.longhorn_default_taint_tolerations : { name = "longhornManager.tolerations[${i}].key" value = split(":", toleration)[0] } ], [ for i, toleration in var.longhorn_default_taint_tolerations : { name = "longhornManager.tolerations[${i}].effect" value = split(":", toleration)[1] } ] )}
resource "kubernetes_manifest" "traefik_ingress_route_longhorn" { manifest = { apiVersion = "traefik.io/v1alpha1" kind = "IngressRoute" metadata = { name = "longhorn" namespace = kubernetes_namespace_v1.longhorn.metadata[0].name } spec = { entryPoints = ["internal"] routes = [ { match = "Host(`longhorn.${var.internal_domain}`)" kind = "Rule" middlewares = [ { name = "internal-basic-auth" namespace = "traefik" } ] services = [ { name = "longhorn-frontend" port = "http" } ] } ] } }}
resource "kubernetes_storage_class_v1" "longhorn_crypto" { metadata { name = "longhorn-crypto" } storage_provisioner = "driver.longhorn.io" parameters = merge( { dataEngine = "v1" dataLocality = "best-effort" fsType = "ext4" numberOfReplicas = var.longhorn_default_local_replica_count diskSelector = "local" encrypted = "true" }, merge( [ for type in [ "provisioner", "node-publish", "node-stage", "node-expand" ] : { "csi.storage.k8s.io/${type}-secret-name" = kubernetes_secret_v1.longhorn_crypto.metadata[0].name "csi.storage.k8s.io/${type}-secret-namespace" = kubernetes_secret_v1.longhorn_crypto.metadata[0].namespace } ]... ) )}
resource "kubernetes_storage_class_v1" "longhorn_crypto_local" { metadata { name = "longhorn-crypto-local" } storage_provisioner = "driver.longhorn.io" parameters = merge( kubernetes_storage_class_v1.longhorn_crypto.parameters, { dataLocality = "strict-local" numberOfReplicas = "1" } )}
resource "kubernetes_storage_class_v1" "longhorn_crypto_volume" { metadata { name = "longhorn-crypto-volume" } storage_provisioner = "driver.longhorn.io" parameters = merge( kubernetes_storage_class_v1.longhorn_crypto.parameters, { numberOfReplicas = var.longhorn_default_volume_replica_count diskSelector = "volume" }, )}Explanation
Nous créons un namespace longhorn-system avec le niveau de sécurité privileged requis par Longhorn.
Nous créons un secret Kubernetes pour stocker les informations d’accès au stockage S3, qui sera utilisé par Longhorn pour stocker les backups, puis un autre pour stocker la clé et paramètres de chiffrement des volumes Longhorn.
Nous déployons Longhorn via Helm avec les configurations suivantes :
- Activation du service monitor pour Prometheus.
- Configuration du stockage de backup avec les informations S3.
- Via
defaultSettings.createDefaultDiskLabeledNodes, on s’assure d’utiliser la configuration indiquée par worker pool à l’étape 2 pour la création des disques par défaut. Le répertoire de point de montage utilisés sur les disques locaux sera/var/lib/longhorn, et/var/mnt/longhornpour les disques externes. - Application des teintes pour que les composants systèmes Longhorn ET Longhorn Manager soient également programmés sur les nœuds de stockage.
Comme d’habitude on définit un IngressRoute Traefik pour exposer l’interface web de Longhorn en interne, toujours protégée par un middleware BasicAuth.
Enfin, dernier point essentiel, nous créons 3 StorageClass :
longhorn-crypto: stockage distribué chiffré, prenant en paramètre le nombre de réplicas par défaut, dédié aux workloads standards. Sera leStorageClasspar défaut lors de la création despvdepuis l’interface UI.longhorn-crypto-local: stockage local chiffré, avec 1 réplica uniquement du fait dustrict-local, dédié aux workloads nécessitant de haute performance en I/O, typiquement les bases de données. Étant ici limité à un seul réplica, ce sera à la partie applicative de gérer la réplication des données, généralement en mode cluster via unStatefulSet.longhorn-crypto-volume: stockage distribué chiffré, avec 2 réplicas, pour les workloads nécessitant un stockage persistant de grande taille.
Plus qu’à lancer un terraform apply pour déployer Longhorn, et tout devrait automatiquement se mettre en place.
Longhorn UI
Sans attendre d’avoir un ingress fonctionnel, vous pouvez déjà vérifier que tout est en ordre en accédant à l’interface web de Longhorn via un kpf -n longhorn-system svc/longhorn-frontend 8000:http et en vous rendant sur http://localhost:8000.
Note
Partie importante en rouge, vous devriez avoir 5 nœuds schedulables.
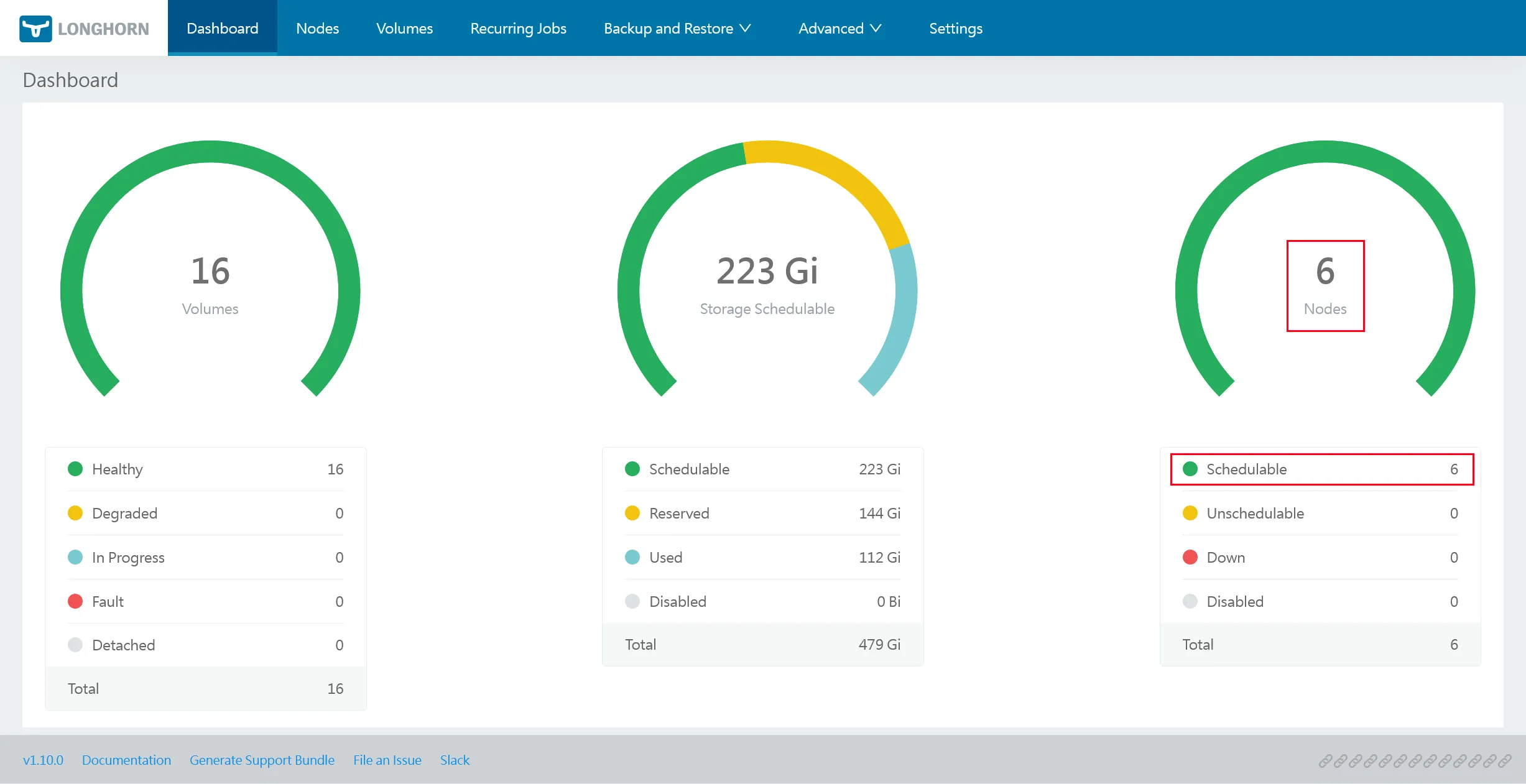
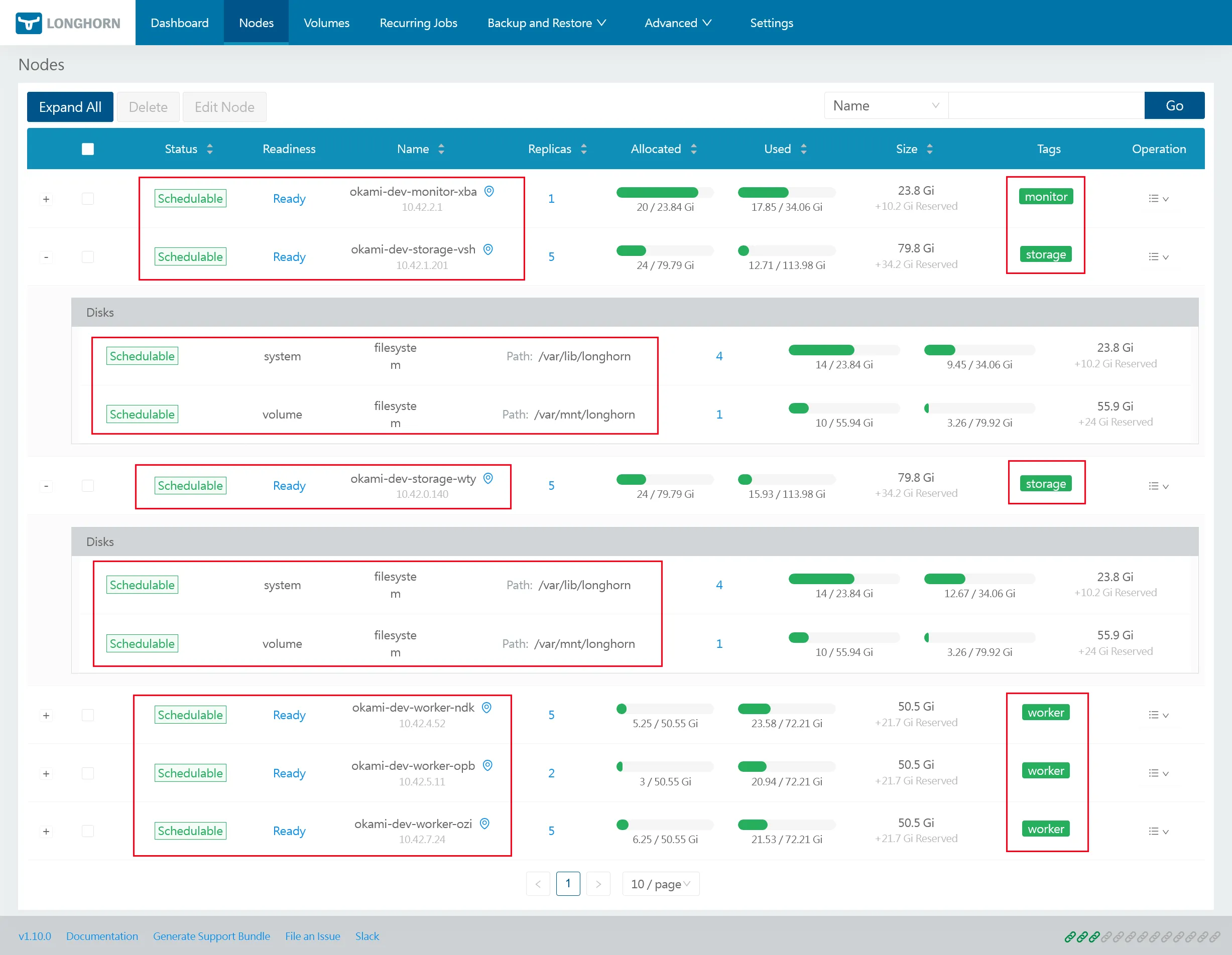
Longhorn Nodes & Disks
Note
Selon la configuration faite à l’étape 2 via les annotations node.longhorn.io/default-disks-config et node.longhorn.io/default-node-tags, chaque nœud doit être correctement étiqueté et avoir un disque local monté sur /var/lib/longhorn, tandis que les nœuds du pool storage doivent avoir en plus un disque externe monté sur /var/mnt/longhorn.
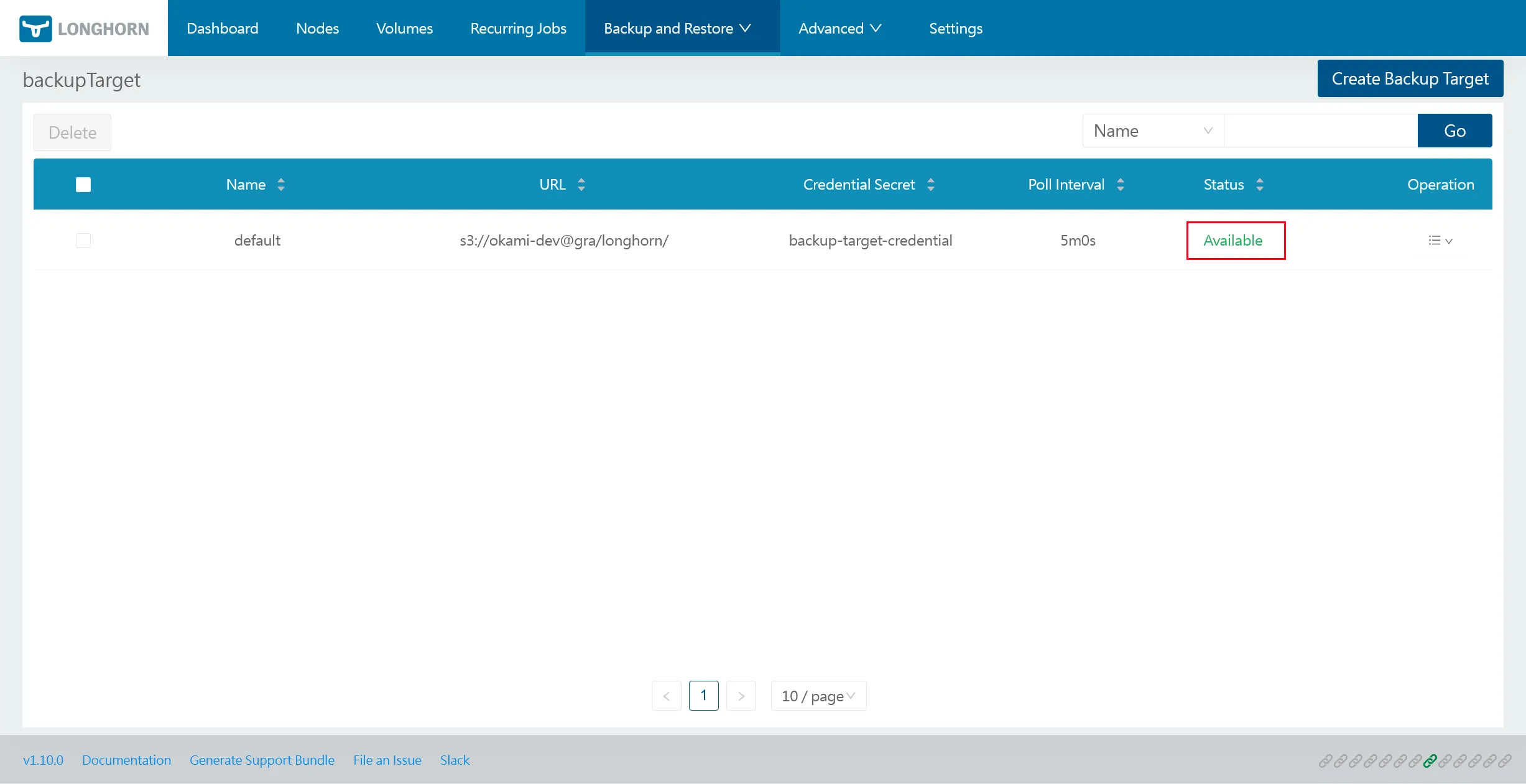
Longhorn Backup
Note
Assurez-vous que le backup target ait bien un statut Available, afin de valider l’accès au S3.
Nous définirons les backups plus tard dans une prochaine section dédiée du guide.
CloudNativePG
Nous allons maintenant nous pencher sur le déploiement de l’opérateur CloudNativePG, qui nous permettra de monter et gérer des clusters de bases de données PostgreSQL, avec réplication, sauvegarde et restauration automatisées.
resource "kubernetes_namespace_v1" "cnpg" { metadata { name = "cnpg-system" }}
resource "helm_release" "cnpg" { repository = "https://cloudnative-pg.github.io/charts" chart = "cloudnative-pg" version = "0.28.0"
name = "cnpg" namespace = kubernetes_namespace_v1.cnpg.metadata[0].name max_history = 2
set = [ { name = "monitoring.podMonitorEnabled" value = "true" }, { name = "monitoring.grafanaDashboard.create" value = "true" } ]}
resource "helm_release" "cnpg_barman_plugin" { repository = "https://cloudnative-pg.github.io/charts" chart = "plugin-barman-cloud" version = "0.6.0"
name = "plugin-barman-cloud" namespace = kubernetes_namespace_v1.cnpg.metadata[0].name max_history = 2
depends_on = [ helm_release.cnpg ]}Explanation
En plus de cnpg, nous installons également l’opérateur plugin-barman-cloud, l’outil de prédilection pour la sauvegarde et restauration de PostgreSQL, avec support du PITR. Il s’intègre parfaitement avec CloudNativePG pour gérer les sauvegardes hors cluster.
Le mode plugin est la nouvelle façon recommandée d’utiliser barman cloud sur les dernières versions de cnpg. De fait, nous utiliserons donc les nouvelles images standard de PostgreSQL fournies par cnpg et dénuées du binaire barman cloud. En mode plugin, le barman cloud s’exécute dans un sidecar séparé, ce qui est plus propre et plus flexible. L’explication ici.
L’activation de monitoring.grafanaDashboard.create permet d’exposer des dashboards Grafana pour les clusters PostgreSQL, que l’on utilisera plus tard dans la section dédiée au monitoring.
Un petit coup de terraform apply et voilà, l’opérateur CloudNativePG est prêt à être utilisé pour la création de clusters PostgreSQL. Nous verrons cela plus tard dans une section dédiée aux bases de données.
Conclusion
Les principaux composants critiques réseaux, CSI et opérateurs de stockage sont désormais en place. Assurez-vous d’avoir un terraform apply propre avant de continuer sur la prochaine partie. Il est enfin temps d’accéder à notre cluster depuis l’extérieur. Suite à la prochaine section pour l’installation de la partie ingress.