
Objectif 🎯
À la fin de la section précédente, nous en avions terminé avec l’ingress. Il s’agirait maintenant d’avoir un vrai service de base de données pour nos applications ainsi des backups chiffrés avec une bonne stratégie. Pour tout cela, nous allons nous appuyer sur les opérateurs déjà installés à la section 4.
Backups
Il y a plusieurs éléments à prendre en compte :
- Backup de l’etcd, cerveau du cluster.
- Backup des volumes persistants critiques, en mode block et/ou en mode fichiers.
- Backup des bases de données en temps réel.
Etcd
Il peut être utile de faire des sauvegardes régulières de notre etcd en cas de situation extrême de devoir restaurer rapidement un cluster défectueux, notamment si un seul nœud control plane unique est envisagé.
Et ça tombe bien, Talos propose un outil taillé pour cela.
Important
La backup de l’etcd ne servira en aucun cas à la création d’un nouveau cluster :
- La construction en mode GitOps rend ce processus inutile et inefficient.
- Les nouvelles machines peuvent avoir des caractéristiques différentes.
- Permet de renouveler tous les certificats.
- Les secrets étant chiffrés à la volée par défaut via Talos, une restauration ne pourrait pas fonctionner, puisque la clé de déchiffrement lié à la nouvelle instance Talos serait nécessairement différente.
module "kube_database" { source = "../../modules/kube/database"
talos_backup_cluster_name = local.cluster_name talos_backup_public_key = var.talos_etcd_backup_age talos_backup_s3_endpoint = "https://${local.s3_endpoint}" talos_backup_s3_region = local.s3_region talos_backup_s3_bucket = local.cluster_name talos_backup_s3_access_key = var.talos_etcd_backup_s3_username talos_backup_s3_secret_key = var.talos_etcd_backup_s3_password}Explanation
Ce qui compte ici sont les accès s3, assez classiques, ainsi que la clé publique age qui servira à chiffrer les backups de l’etcd avant leur envoi vers le stockage distant.
// ...
variable "talos_etcd_backup_age" { type = string sensitive = true}
variable "talos_etcd_backup_s3_username" { type = string}
variable "talos_etcd_backup_s3_password" { type = string sensitive = true}fnox set TF_VAR_talos_etcd_backup_age "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_talos_etcd_backup_s3_username "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_talos_etcd_backup_s3_password "xxxxxxxxxxxxxxxxxxxxx" --provider age// ...
variable "talos_backup_cluster_name" { description = "The name of the cluster" type = string}
variable "talos_backup_public_key" { description = "The age public key for encryption of the backup" type = string}
variable "talos_backup_s3_endpoint" { description = "The endpoint of the S3 compatible storage" type = string}
variable "talos_backup_s3_access_key" { description = "The access key for the S3 compatible storage" type = string}
variable "talos_backup_s3_secret_key" { description = "The secret key for the S3 compatible storage" type = string sensitive = true}
variable "talos_backup_s3_region" { description = "The region of the S3 compatible storage" type = string}
variable "talos_backup_s3_bucket" { description = "The bucket of the S3 compatible storage" type = string}resource "kubernetes_cron_job_v1" "talos_backup" { metadata { name = "talos-backup" namespace = "kube-system" }
spec { schedule = "@hourly"
job_template { metadata { name = "talos-backup" } spec { template { metadata { name = "talos-backup" } spec { container { name = "talos-backup" image = "ghcr.io/siderolabs/talos-backup:latest" working_dir = "/tmp" image_pull_policy = "IfNotPresent"
env { name = "AWS_ACCESS_KEY_ID" value = var.talos_backup_s3_access_key } env { name = "AWS_SECRET_ACCESS_KEY" value_from { secret_key_ref { name = kubernetes_secret_v1.talos_s3_secrets.metadata[0].name key = "s3_secret_key" } } } env { name = "AWS_REGION" value = var.talos_backup_s3_region } env { name = "CUSTOM_S3_ENDPOINT" value = var.talos_backup_s3_endpoint } env { name = "BUCKET" value = var.talos_backup_s3_bucket } env { name = "CLUSTER_NAME" value = var.talos_backup_cluster_name } env { name = "S3_PREFIX" value = "etcd" } env { name = "AGE_X25519_PUBLIC_KEY" value = var.talos_backup_public_key } env { name = "ENABLE_COMPRESSION" value = "true" }
security_context { run_as_user = 1000 run_as_group = 1000 allow_privilege_escalation = false run_as_non_root = true
capabilities { drop = ["ALL"] } seccomp_profile { type = "RuntimeDefault" } }
command = ["/talos-backup"]
volume_mount { mount_path = "/tmp" name = "tmp" } volume_mount { mount_path = "/.talos" name = "talos" } volume_mount { mount_path = "/var/run/secrets/talos.dev" name = "talos-secrets" } }
restart_policy = "OnFailure"
volume { name = "tmp" empty_dir {} } volume { name = "talos" empty_dir {} } volume { name = "talos-secrets" secret { secret_name = kubernetes_manifest.talos_backup_service_account.manifest.metadata.name } } } } } } }}
resource "kubernetes_secret_v1" "talos_s3_secrets" { metadata { name = "talos-s3-secrets" namespace = "kube-system" } data = { s3_secret_key = var.talos_backup_s3_secret_key }}
resource "kubernetes_manifest" "talos_backup_service_account" { manifest = { apiVersion = "talos.dev/v1alpha1" kind = "ServiceAccount" metadata = { name = "talos-backup-secrets" namespace = "kube-system" } spec = { roles = ["os:etcd:backup"] } }}Explanation
Nous ne faisons que reprendre l’exemple officiel. Backup toutes les heures. La gestion de rétention n’est pas incluse, mais il reste toujours la possibilité de le faire via des règles de cycle de vie sur le bucket S3.
Longhorn
La backup côté stockage persistant est assurée par Longhorn, uniquement en mode block. Il suffit de créer des objets RecurringJob pour définir la fréquence et la rétention des backups.
resource "kubernetes_manifest" "longhorn_jobs" { for_each = { daily = { cron = "0 0 * * *" retain = 7 }, weekly = { cron = "0 3 * * 1" retain = 4 } monthly = { cron = "0 6 1 * *" retain = 3 } } manifest = { apiVersion = "longhorn.io/v1beta2" kind = "RecurringJob" metadata = { name = each.key namespace = "longhorn-system" } spec = { concurrency = 1 cron = each.value.cron groups = ["backup"] name = each.key retain = each.value.retain task = "backup" } }}La stratégie classique de backup décrite ci-dessus est la suivante :
- Backup quotidien, conservé 7 jours.
- Backup hebdomadaire, conservé 4 semaines.
- Backup mensuel, conservé 3 mois.
Très facile à adapter selon vos besoins. De plus, du fait de la nature même de la sauvegarde en mode block, son chiffrement est déjà assuré sur les volumes chiffrés.
Après application, vous devriez les retrouver dans l’interface web de Longhorn :
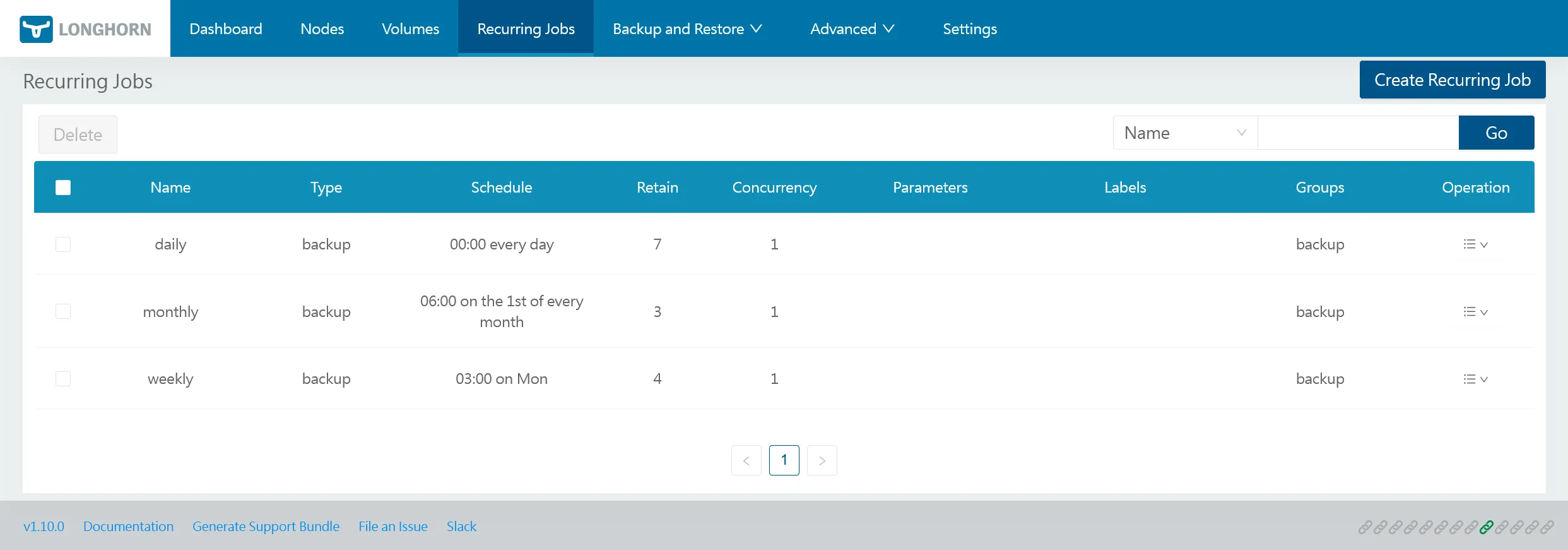
Par défaut, seuls les volumes placés dans le groupe backup seront concernés par les jobs de backup. Ce n’est pas le cas par défaut, il faudra donc les définir explicitement dans l’onglet Volumes. Je préfère explicitement choisir quels volumes doivent être sauvegardés ou non mais libre à vous de changer votre stratégie.
Base de données
Qu’est-ce qu’un kube sans cluster de base de données ? Pour garder la maîtrise des coûts et de toute la chaîne de l’infra, nous préférerions éviter les services managés. Bien que ces derniers facilitent réellement la vie des développeurs qui n’ont pas envie de se prendre la tête avec la gestion des bases et toute ce qui va avec (réplication, backups, etc.), l’arrivée de puissants opérateurs tels que CloudNativePG facilitent grandement la mise en œuvre et gestion du cycle de vie de clusters PostgreSQL.
Dragonfly
On commence par un truc simple, Dragonfly, une base de données en mémoire performante et compatible avec le protocole Redis.
module "kube_database" { // ...
dragonfly_password = var.dragonfly_password}// ...
variable "dragonfly_password" { type = string sensitive = true}fnox set TF_VAR_dragonfly_password "xxxxxxxxxxxxxxxxxxxxx" --provider age// ...
variable "dragonfly_password" { description = "The password for the dragonfly" type = string sensitive = true}resource "kubernetes_namespace_v1" "dragonfly" { metadata { name = "dragonfly" }}
resource "kubernetes_secret_v1" "dragonfly_auth" { metadata { name = "dragonfly-auth" namespace = kubernetes_namespace_v1.dragonfly.metadata[0].name } data = { dragonfly-password = var.dragonfly_password }}
resource "helm_release" "dragonfly" { repository = "oci://ghcr.io/dragonflydb/dragonfly/helm" chart = "dragonfly" version = "v1.38.0"
name = "dragonfly" namespace = kubernetes_namespace_v1.dragonfly.metadata[0].name max_history = 2
set = [ { name = "replicaCount" value = "2" }, { name = "passwordFromSecret.enable" value = "true" }, { name = "passwordFromSecret.existingSecret.name" value = kubernetes_secret_v1.dragonfly_auth.metadata[0].name }, { name = "passwordFromSecret.existingSecret.key" value = "dragonfly-password" }, { name = "tolerations[0].key" value = "node-role.kubernetes.io/storage" }, { name = "tolerations[0].operator" value = "Exists" }, { name = "nodeSelector.node\\.kubernetes\\.io/role" value = "storage" }, { name = "storage.enabled" value = "true" }, { name = "storage.storageClassName" value = "longhorn-crypto-local" }, { name = "storage.requests" value = "2Gi" }, { name = "serviceMonitor.enabled" value = "true" } ]}Explanation
On s’assure de l’installer sur les nœuds de storage, grâce aux tolerations et nodeSelector. Le stockage persistant est assuré par un volume Longhorn chiffré. L’installation étant en mode cluster, 2 StatefulSets sont créés avec chacun leur propre volume. La réplication étant déjà assuré par Dragonfly, et pour maximiser les performances I/O, nous utilisons le StorageClass longhorn-crypto-local qui utilise des volumes Longhorn en local strict.
CloudNativePG
On s’attaque au plus gros sujet. De la même manière que pour Dragonfly, nous allons installer un cluster PostgreSQL mais construit via l’opérateur CloudNativePG. Le même principe s’applique sur les volumes Longhorn en mode local strict, pour maximiser les perfs IO.
On gérera dans le même temps les backups de la base de données via le plugin barman-cloud qui permettra de faire des backups sur notre S3.
Le schéma qui résume la stack CloudNativePG cible :

Barman operator, en plus de la politique de rétention, est donc en charge de fournir à l’opérateur principal les spécifications nécessaires à la génération du sidecar barman lors de la création d’une instance PostgreSQL.
Important
Il est essentiel d’avoir 2 modes de backups :
- Backup de base quotidienne, voire hebdomadaire, via le plugin
barman-cloud(mode fichier). - Backup incrémental en quasi-temps réel, via le plugin
barman-clouduniquement, par sauvegarde des fichiers WAL (Write-Ahead Logging), éléments essentiels sur lequel s’appuie le mode Point in Time recovery (PITR). Le principe est de sauvegarder en continu les fichiers WAL, qui permettent de rejouer toutes les transactions effectuées sur la base de données depuis le dernier backup full.
module "kube_database" { // ...
cnpg_cluster_name = local.cluster_name cnpg_pg_version = "18.3-standard-trixie"
cnpg_backup_s3_endpoint = "https://${local.s3_endpoint}" cnpg_backup_s3_access_key = var.cnpg_backup_s3_username cnpg_backup_s3_secret_key = var.cnpg_backup_s3_password cnpg_backup_s3_bucket = local.cluster_name}Explanation
Le choix de la version est importante, choisissez le bon tag ici selon vos besoins. Ici nous prenons la dernière version stable au moment de l’écriture de ce guide, la 18, sous debian 13. Ne pas prendre les versions dépréciées system qui ne sont pas compatibles avec les plugins de backup.
Il faudra indiquer les accès S3 pour les backups, qui seront gérés par l’opérateur le plugin CNPG-I barman-cloud.
// ...
variable "cnpg_backup_s3_username" { type = string}
variable "cnpg_backup_s3_password" { type = string sensitive = true}fnox set TF_VAR_cnpg_backup_s3_username "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_cnpg_backup_s3_password "xxxxxxxxxxxxxxxxxxxxx" --provider age// ...
variable "cnpg_cluster_name" { description = "The name of the cluster" type = string}
variable "cnpg_pg_version" { description = "The version of the PostgreSQL" type = string}
variable "cnpg_backup_s3_endpoint" { description = "The endpoint of the S3 compatible storage" type = string}
variable "cnpg_backup_s3_access_key" { description = "The access key for the S3 compatible storage" type = string}
variable "cnpg_backup_s3_secret_key" { description = "The secret key for the S3 compatible storage" type = string sensitive = true}
variable "cnpg_backup_s3_bucket" { description = "The bucket of the S3 compatible storage" type = string}resource "kubernetes_namespace_v1" "postgres" { metadata { name = "postgres" }}
resource "kubernetes_manifest" "cnpg_cluster_default" { manifest = { apiVersion = "postgresql.cnpg.io/v1" kind = "Cluster" metadata = { name = var.cnpg_cluster_name namespace = kubernetes_namespace_v1.postgres.metadata[0].name } spec = { imageName = "ghcr.io/cloudnative-pg/postgresql:${var.cnpg_pg_version}" description = "PostgreSQL dev" instances = 2
bootstrap = { initdb = { database = "app" owner = "app" } }
enableSuperuserAccess = true
storage = { size = "8Gi" storageClass = "longhorn-crypto-local" }
affinity = { tolerations = [ { key = "node-role.kubernetes.io/storage" operator = "Exists" } ] nodeSelector = { "node.kubernetes.io/role" = "storage" } }
plugins = [ { name = "barman-cloud.cloudnative-pg.io" isWALArchiver = true parameters = { serverName = var.cnpg_cluster_name barmanObjectName = kubernetes_manifest.cnpg_object_store_backup_default.manifest.metadata.name } } ] } }}
resource "kubernetes_manifest" "cnpg_pod_monitor" { manifest = { apiVersion = "monitoring.coreos.com/v1" kind = "PodMonitor" metadata = { name = "${var.cnpg_cluster_name}-cluster" namespace = kubernetes_namespace_v1.postgres.metadata[0].name } spec = { podMetricsEndpoints = [ { port = "metrics" } ] selector = { matchLabels = { "cnpg.io/cluster" = var.cnpg_cluster_name } } } }}
resource "kubernetes_secret_v1" "cnpg_backup_s3" { metadata { name = "backup-s3" namespace = kubernetes_namespace_v1.postgres.metadata[0].name } data = { ACCESS_KEY_ID = var.cnpg_backup_s3_access_key ACCESS_SECRET_KEY = var.cnpg_backup_s3_secret_key }}
resource "kubernetes_manifest" "cnpg_object_store_backup_default" { manifest = { apiVersion = "barmancloud.cnpg.io/v1" kind = "ObjectStore" metadata = { name = "${var.cnpg_cluster_name}-backup" namespace = kubernetes_namespace_v1.postgres.metadata[0].name } spec = { retentionPolicy = "30d" configuration = { endpointURL = var.cnpg_backup_s3_endpoint destinationPath = "s3://${var.cnpg_backup_s3_bucket}/cnpg/" data = { compression = "bzip2" encryption = "AES256" } wal = { compression = "bzip2" encryption = "AES256" } s3Credentials = { accessKeyId = { name = kubernetes_secret_v1.cnpg_backup_s3.metadata[0].name key = "ACCESS_KEY_ID" } secretAccessKey = { name = kubernetes_secret_v1.cnpg_backup_s3.metadata[0].name key = "ACCESS_SECRET_KEY" } } } } }}
resource "kubernetes_manifest" "cnpg_scheduled_backup_barman_default" { manifest = { apiVersion = "postgresql.cnpg.io/v1" kind = "ScheduledBackup" metadata = { name = "${var.cnpg_cluster_name}-barman" namespace = kubernetes_namespace_v1.postgres.metadata[0].name } spec = { method = "plugin" schedule = "@daily" backupOwnerReference = "self" immediate = true cluster = { name = kubernetes_manifest.cnpg_cluster_default.manifest.metadata.name } pluginConfiguration = { name = "barman-cloud.cloudnative-pg.io" } } }}Explanation
Pas de Helm ici, on utilise les CRDs natifs installés par l’opérateur cnpg. On s’assure encore une fois de l’installer sur les nœuds de storage, grâce aux tolerations et nodeSelector.
Pour la partie backup complète, cela passe par la définition d’un ScheduledBackup, utilisant la méthode barman-cloud. On l’associe avec le CRD ObjectStore spécifique à l’opérateur barman, il sera utilisé à la fois pour le backup full et pour le backup des fichiers WAL défini dans les paramètres du cluster.
Après l’habituel terraform apply, vérifier le status des pods postgres via kgp -n postgres -o wide. A un plus haut niveau, vérifier le status du cluster via k cnpg status ohmytalos-dev -n postgres pour avoir quelque chose ressemblant à ceci :
Cluster SummaryName postgres/ohmytalos-devSystem ID: 7554694612884451350PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:18-standard-trixiePrimary instance: ohmytalos-dev-1Primary start time: 2025-09-27 10:10:48 +0000 UTC (uptime 150h53m23s)Status: Cluster in healthy stateInstances: 2Ready instances: 2Size: 1.1GCurrent Write LSN: E2/72001CB8 (Timeline: 2 - WAL File: 00000002000000E200000072)
Continuous Backup statusFirst Point of Recoverability: 2025-09-27T10:13:34ZWorking WAL archiving: OKWALs waiting to be archived: 0Last Archived WAL: 00000002000000E200000071 @ 2025-10-03T17:03:05.124893ZLast Failed WAL: 00000002.history @ 2025-09-27T10:10:17.393725Z
Streaming Replication statusReplication Slots EnabledName Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority Replication Slot---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- ------------- ----------------ohmytalos-dev-2 E2/72001CB8 E2/72001CB8 E2/72001CB8 E2/72001CB8 00:00:00 00:00:00 00:00:00 streaming async 0 active
Instances statusName Current LSN Replication role Status QoS Manager Version Node---- ----------- ---------------- ------ --- --------------- ----ohmytalos-dev-1 E2/72001CB8 Primary OK Burstable 1.27.0 ohmytalos-dev-storage-wtyohmytalos-dev-2 E2/72001CB8 Standby (async) OK Burstable 1.27.0 ohmytalos-dev-storage-vsh
Plugins statusName Version Status Reported Operator Capabilities---- ------- ------ ------------------------------barman-cloud.cloudnative-pg.io 0.7.0 N/A Reconciler Hooks, Lifecycle ServiceCôté backup, le mode immediate étant activé, vous devriez déjà voir une backup complète apparaître sur votre s3, ainsi que les 1ers WALs.
pgAdmin
Pour bien faire il nous faudrait un petit pgadmin pour gérer nos bases de données PostgreSQL. Rien de plus simple avec ce chart.
module "kube_database" { // ...
internal_domain = local.internal_domain pgadmin_email = "admin@ohmytalos.io"}// ...
variable "internal_domain" { description = "The internal domain" type = string}
variable "pgadmin_email" { description = "The email of the admin pgAdmin user" type = string}resource "kubernetes_namespace_v1" "pgadmin" { metadata { name = "pgadmin" }}
resource "helm_release" "pgadmin" { repository = "https://helm.runix.net" chart = "pgadmin4" version = "1.62.0"
name = "pgadmin" namespace = kubernetes_namespace_v1.pgadmin.metadata[0].name max_history = 2
set = [ { name = "strategy.type" value = "Recreate" }, { name = "env.email" value = var.pgadmin_email }, { name = "persistentVolume.storageClass" value = "longhorn-crypto" } ]}
resource "kubernetes_manifest" "traefik_ingress_route_pgadmin" { manifest = { apiVersion = "traefik.io/v1alpha1" kind = "IngressRoute" metadata = { name = "pgadmin" namespace = kubernetes_namespace_v1.pgadmin.metadata[0].name } spec = { entryPoints = ["internal"] routes = [ { match = "Host(`pga.${var.internal_domain}`)" kind = "Rule" services = [ { name = "pgadmin-pgadmin4" port = "http" } ] } ] } }}Voilà simple et basique, après terraform apply, go sur https://pga.dev.ohmytalos.io et rentrer les identifiants admin@ohmytalos.io + SuperSecret, puis changer ce mot de passe par défaut (il sera stocké dans la base sqlite persisté dans le volume).
Il vous reste plus qu’à ajouter vos serveurs PostgreSQL. CloudNativePG propose 3 services d’accès, pour reprendre le nom donnée à notre cluster, nous avons :
ohmytalos-dev-rw.postgres: La base primary active, avec accès en écriture. L’opérateur s’occupe de la bascule automatique en cas de défaillance détectée en promouvant un des replicas disponibles.ohmytalos-dev-ro.postgres: Le(s) base(s) standby, avec accès en lecture seule, dont les données sont répliquées depuis le primary. Les backups s’effectuent uniquement via ces bases pour ne pas surcharger la primary.ohmytalos-dev-r.postgres: Tous les serveurs PostgreSQL sans distinction. Très utile dans notre cas (2 serveurs uniquement) pour les applications voulant distribuer la lecture sur toutes les bases.
Créer un accès pour la primary et un autre pour les replicas, comme suit :
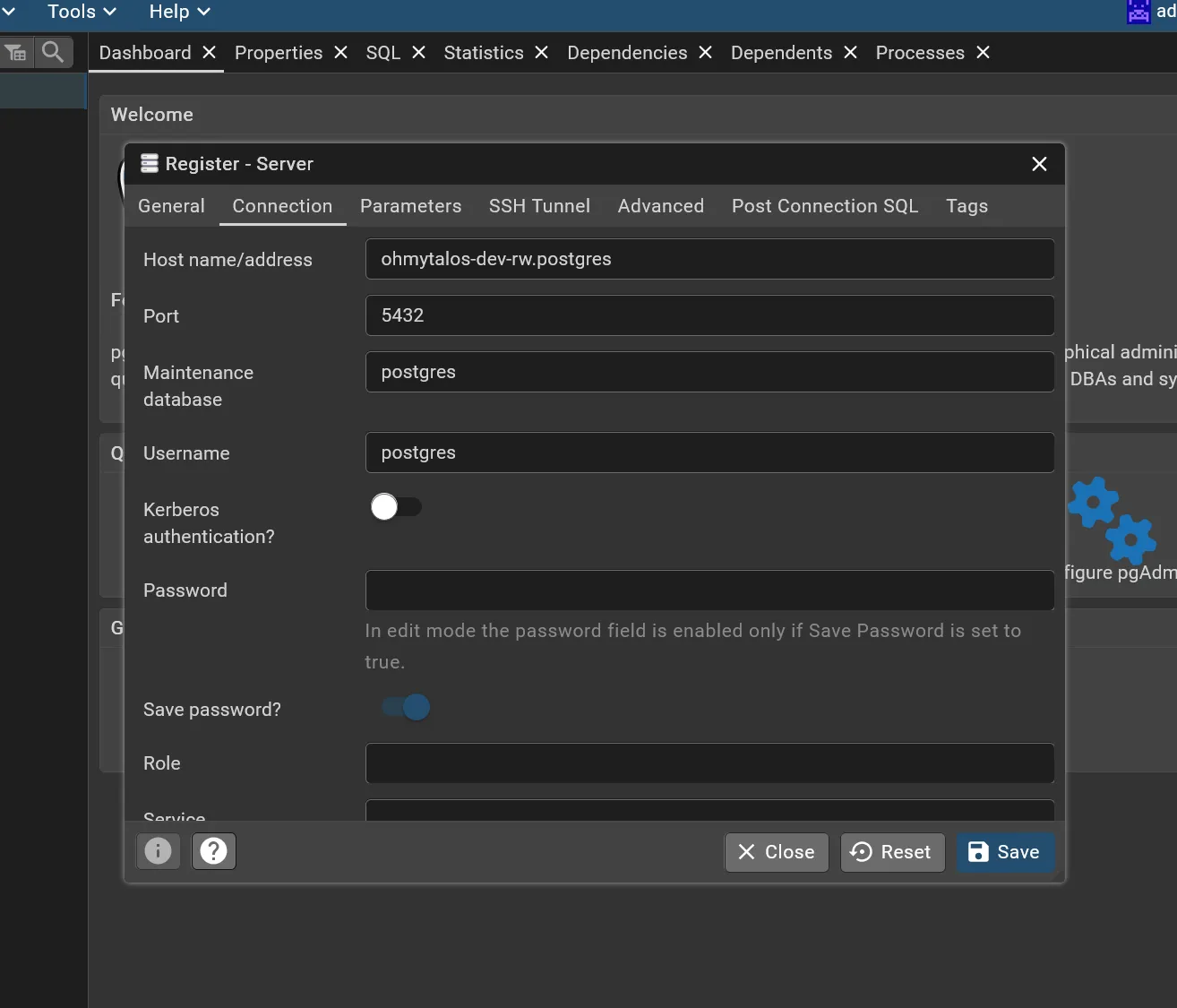
Vous pouvez récupérer le mot de passe généré aléatoirement lors de la création du cluster via la commande kgsec -n postgres -o yaml okami-dev-superuser | yq -r .data.password | base64 -d.
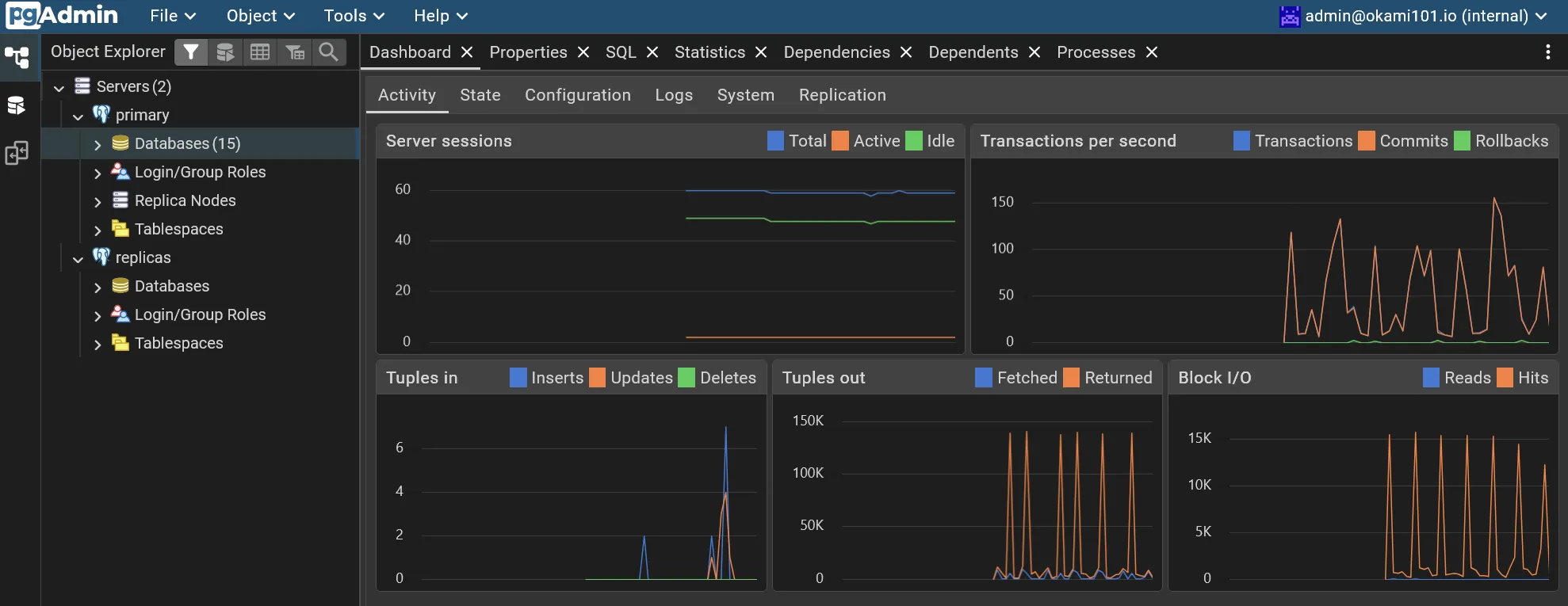
Libre à vous de déclencher des backups logiques, via l’interface pgAdmin, en plus des backups automatiques déjà mis en place. Elles seront stockées dans le volume persistant de pgAdmin, d’une taille à 10 Gio par défaut.
Conclusion
Et voilà qu’on est bien. Il nous manque un dernier gros maillon critique pour un cluster de pro, la stack d’observabilité. C’est ce que nous verrons dans la section suivante.