
Objectif 🎯
La mise en place des backups et base de données étant faite, il nous manque les derniers composants critiques d’un cluster de production, à savoir tout ce qui concerne l’observabilité à tous les niveaux, à savoir le triptyque métriques, logging, et traçabilité.
Networking
Cilium fourni déjà son propre outil d’observabilité réseau temps réel, que l’on a déjà installé à l’étape 3.
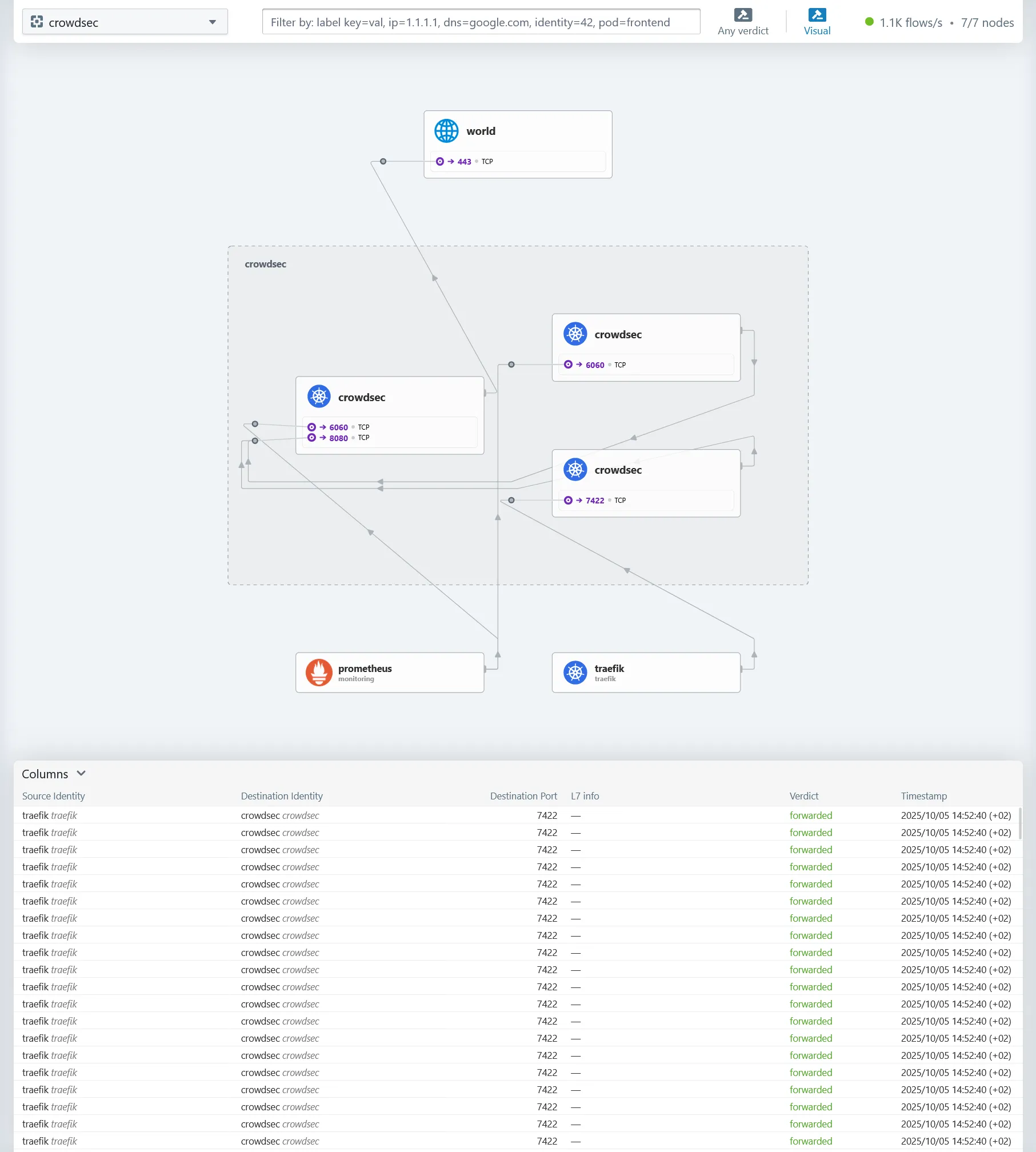
Pour Cilium il s’agit de Hubble, accessible sur https://hubble.dev.ohmytalos.io, son outil de visualisation eBPF, très utile pour visualiser les interactions réseau entre les composants. Exemple sur le namespace CrowdSec :
Métriques 📊
Sur l’ensemble des charts helm préalablement installés, nous nous sommes assurés d’activer tous les ServiceMonitor afin que Prometheus puisse aller scraper les métriques exposées par tous les composants critiques du système sans que l’on ait à définir de configuration supplémentaire. Il nous reste plus qu’à installer un cluster Prometheus, de préférence sur nos nœuds de storage.
L’architecture de la stack Prometheus :

module "kube_monitoring" { source = "../../modules/kube/monitoring"
internal_domain = local.internal_domain control_planes_ips = [ for s in data.hcloud_servers.control_planes.servers : tolist(s.network)[0].ip ]
smtp_host = "smtp.tem.scaleway.com:465"
alertmanager_smtp_username = var.alertmanager_smtp_username alertmanager_smtp_password = var.alertmanager_smtp_password alertmanager_from = "prom.dev@ohmytalos.io" alertmanager_to = "me@ohmytalos.io"}Explanation
Afin de scraper les métriques des composants centraux du kubernetes, notamment l’etcd, le scheduler ainsi que le controller manager, nous avons besoin d’envoyer au chart prometheus les IPs privées des nœuds de control plane. Nous utilisons donc la data source hcloud_servers déjà déclaré lors du chapitre sur l’ingress pour récupérer ces informations dynamiquement.
Nous configurons également les informations nécessaires pour qu’Alertmanager puisse envoyer des notifications par email via SMTP.
// ...
variable "internal_domain" { description = "The internal domain to use for the cluster" type = string}
variable "control_planes_ips" { description = "List of control plane IPs" type = list(string)}
variable "smtp_host" { description = "The SMTP host" type = string}
variable "alertmanager_smtp_username" { description = "The SMTP username for Alertmanager" type = string}
variable "alertmanager_smtp_password" { description = "The SMTP password for Alertmanager" type = string sensitive = true}
variable "alertmanager_from" { description = "The email address to send Alertmanager notifications from" type = string}
variable "alertmanager_to" { description = "The email address to send Alertmanager notifications to" type = string}// ...
variable "alertmanager_smtp_username" { type = string}
variable "alertmanager_smtp_password" { type = string sensitive = true}fnox set TF_VAR_alertmanager_smtp_username "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_alertmanager_smtp_password "xxxxxxxxxxxxxxxxxxxxx" --provider ageresource "kubernetes_namespace_v1" "monitoring" { metadata { name = "monitoring" labels = { "pod-security.kubernetes.io/enforce" = "privileged" } }}
resource "helm_release" "prometheus" { repository = "https://prometheus-community.github.io/helm-charts" chart = "kube-prometheus-stack" version = "84.2.1"
name = "prometheus" namespace = kubernetes_namespace_v1.monitoring.metadata[0].name max_history = 2
set = [ { name = "prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues" value = "false" }, { name = "prometheus.prometheusSpec.podMonitorSelectorNilUsesHelmValues" value = "false" }, { name = "grafana.enabled" value = "false" }, { name = "grafana.forceDeployDatasources" value = "true" }, { name = "grafana.forceDeployDashboards" value = "true" }, { name = "kubeProxy.enabled" value = "false" }, { name = "crds.enabled" value = "false" }, { name = "prometheus.prometheusSpec.replicas" value = "2" }, { name = "prometheus.prometheusSpec.enableRemoteWriteReceiver" value = "true" }, { name = "prometheus.prometheusSpec.enableOTLPReceiver" value = "true" }, { name = "prometheus.prometheusSpec.remoteWriteDashboards" value = "true" }, { name = "prometheus.prometheusSpec.storageSpec.volumeClaimTemplate.spec.accessModes[0]" value = "ReadWriteOnce" }, { name = "prometheus.prometheusSpec.storageSpec.volumeClaimTemplate.spec.resources.requests.storage" value = "20Gi" }, { name = "prometheus.prometheusSpec.storageSpec.volumeClaimTemplate.spec.storageClassName" value = "longhorn-crypto-local" }, { name = "prometheus.prometheusSpec.tolerations[0].key" value = "node-role.kubernetes.io/storage" }, { name = "prometheus.prometheusSpec.tolerations[0].operator" value = "Exists" }, { name = "prometheus.prometheusSpec.nodeSelector.node\\.kubernetes\\.io/role" value = "storage" }, { name = "prometheus.prometheusSpec.externalUrl" value = "https://prom.${var.internal_domain}" }, { name = "alertmanager.alertmanagerSpec.replicas" value = "2" }, { name = "alertmanager.alertmanagerSpec.storage.volumeClaimTemplate.spec.accessModes[0]" value = "ReadWriteOnce" }, { name = "alertmanager.alertmanagerSpec.storage.volumeClaimTemplate.spec.resources.requests.storage" value = "2Gi" }, { name = "alertmanager.alertmanagerSpec.storage.volumeClaimTemplate.spec.storageClassName" value = "longhorn-crypto" }, { name = "alertmanager.alertmanagerSpec.externalUrl" value = "https://am.${var.internal_domain}" }, { name = "grafana.sidecar.datasources.exemplarTraceIdDestinations.datasourceUid" value = "tempo" }, { name = "grafana.sidecar.datasources.exemplarTraceIdDestinations.traceIdLabelName" value = "trace_id" }, { name = "grafana.sidecar.datasources.exemplarTraceIdDestinations.urlDisplayLabel" value = "View traces" } ]
set_list = [ { name = "kubeControllerManager.endpoints" value = var.control_planes_ips }, { name = "kubeScheduler.endpoints" value = var.control_planes_ips }, { name = "kubeEtcd.endpoints" value = var.control_planes_ips }, { name = "prometheus.prometheusSpec.otlp.promoteResourceAttributes" value = [ "service.instance.id", "service.name", ] }, { name = "prometheus.prometheusSpec.enableFeatures" value = [ "exemplar-storage", ] } ]}
resource "kubernetes_manifest" "traefik_ingress_route_prometheus" { manifest = { apiVersion = "traefik.io/v1alpha1" kind = "IngressRoute" metadata = { name = "prometheus" namespace = kubernetes_namespace_v1.monitoring.metadata[0].name } spec = { entryPoints = ["internal"] routes = [ { match = "Host(`prom.${var.internal_domain}`)" kind = "Rule" middlewares = [ { name = "internal-basic-auth" namespace = "traefik" } ] services = [ { name = "prometheus-operated" port = "http-web" } ] } ] } }}
resource "kubernetes_manifest" "traefik_ingress_route_alertmanager" { manifest = { apiVersion = "traefik.io/v1alpha1" kind = "IngressRoute" metadata = { name = "alertmanager" namespace = kubernetes_namespace_v1.monitoring.metadata[0].name } spec = { entryPoints = ["internal"] routes = [ { match = "Host(`am.${var.internal_domain}`)" kind = "Rule" middlewares = [ { name = "internal-basic-auth" namespace = "traefik" } ] services = [ { name = "alertmanager-operated" port = "http-web" } ] } ] } }}
resource "kubernetes_secret_v1" "alertmanager_smtp" { metadata { name = "alertmanager-smtp" namespace = kubernetes_namespace_v1.monitoring.metadata[0].name }
data = { password = var.alertmanager_smtp_password }}
resource "kubernetes_manifest" "alertmanager_config_email" { manifest = { apiVersion = "monitoring.coreos.com/v1alpha1" kind = "AlertmanagerConfig" metadata = { name = "email" namespace = kubernetes_namespace_v1.monitoring.metadata[0].name } spec = { receivers = [ { emailConfigs = [ { authUsername = var.alertmanager_smtp_username authPassword = { key = "password" name = kubernetes_secret_v1.alertmanager_smtp.metadata[0].name } smarthost = var.smtp_host from = var.alertmanager_from to = var.alertmanager_to sendResolved = true requireTLS = false } ] name = "email-notifications" } ] route = { matchers = [ { matchType = "=" name = "severity" value = "critical" } ] receiver = "email-notifications" } } }}Explanation
Nous configurons le chart helm pour qu’il utilise des ServiceMonitor et PodMonitor afin de scraper automatiquement les métriques exposées par les composants du cluster.
Le composant kubeProxy étant remplacé par cilium, penser à le désactiver. Le chart déploiera également un subchart node-exporter qui sera en charge de déployer des DaemonSets sur chaque nœud pour récupérer leurs métriques.
Ce chart étant suffisamment lourd comme ça, nous désactivons Grafana car je préfère l’installer séparément plus tard. Mais nous forçons le déploiement des dashboards pour kubernetes par défaut qui sont déjà très complets afin de les récupérer au moment de l’installation de Grafana.
On configure 2 replicas de prometheus que l’on dispatche sur les nœuds de stockage via des tolerations et nodeSelector. Nous configurons également le stockage persistant en localité stricte sur Longhorn.
Quant à Alertmanager, nous le déployons en mode cluster 2 réplicas, avec une persistence StorageClass longhorn-crypto uniquement. Pas besoin de haute perfo pour ça et cela permet de rester flexible sur l’emplacement des instances alertmanager.
Nous activons les récepteurs enableRemoteWriteReceiver et enableOTLPReceiver qui nous servirons plus tard, particulièrement dans la corrélation avec les traces et logs. Autre détail du fait de l’utilisation de OTLP, on anticipe de préconfigurer exemplarTraceIdDestinations au niveau de la datasource prometheus Grafana, ceci nous permettra de lier les exemplars (sorte de références événementielles) aux futures traces générées par tempo. À ce titre, il est nécessaire d’activer la feature exemplar-storage pour stocker ce type de structure. Enfin configurer promoteResourceAttributes pour promouvoir quelques attributs de ressource OTLP en tant qu’étiquettes Prometheus.
Nous créons les routes d’ingress Traefik pour accéder à Prometheus et Alertmanager via des sous-domaines internes sécurisés par une authentification basique. Adapter les valeurs externalUrl dans le chart helm pour générer les bonnes URLs dans les alertes.
Enfin, nous créons une nouvelle ressource AlertmanagerConfig pour envoyer des notifications par email via SMTP. Ce sera l’alerte par défaut pour toutes les alertes de sévérité critical. Libre à vous de rajouter d’autres récepteurs et routes selon vos besoins.
Déployer tout ça et aller sur l’interface web de Prometheus via https://prom.dev.ohmytalos.io.
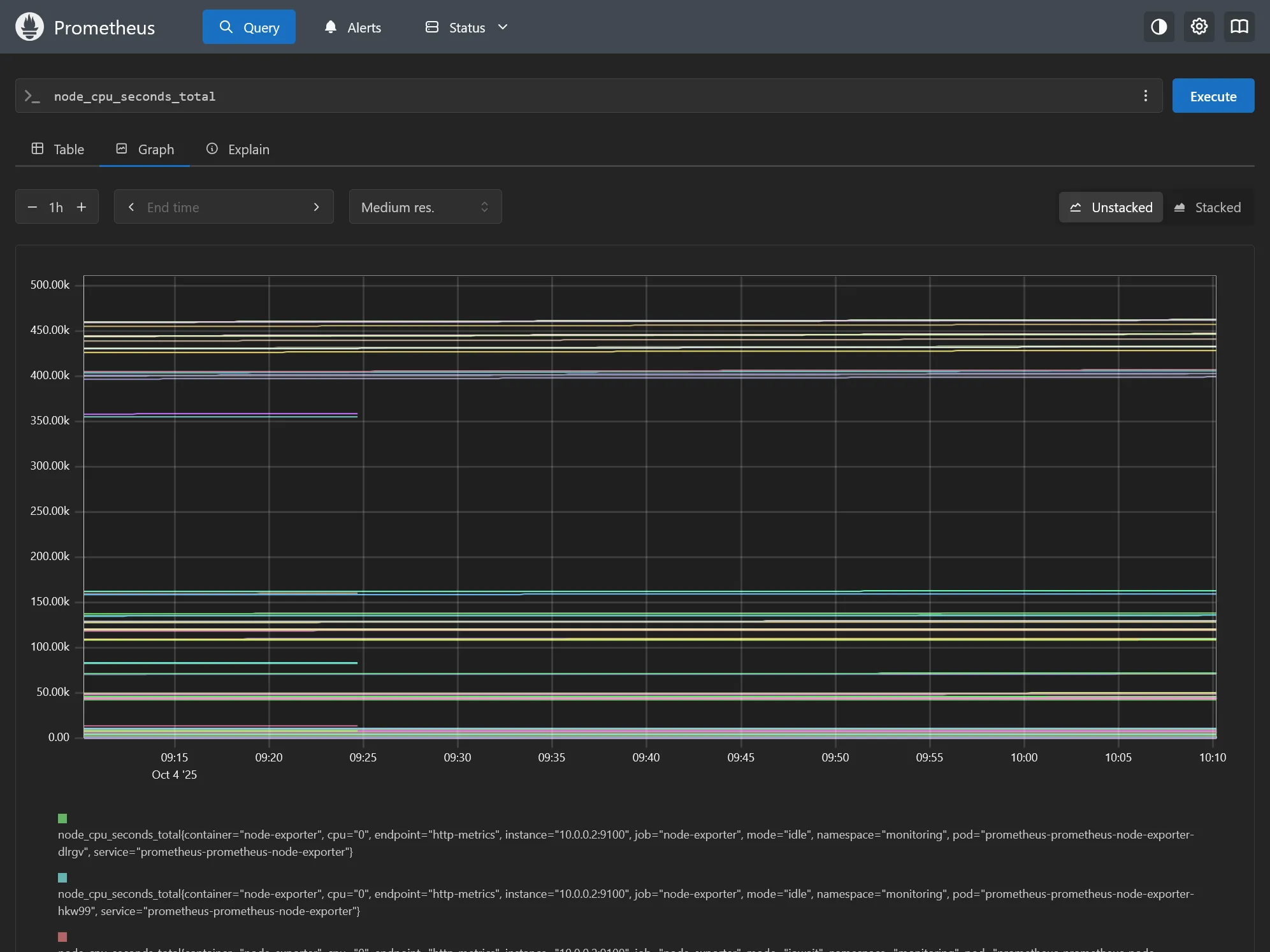
Le plus intéressant dans l’immédiat est d’aller voir dans la section Targets pour vérifier que tous les endpoints sont bien scrappés, tout devrait déjà être à UP.
Faites également un tour sur https://am.dev.ohmytalos.io (attention pas de dark mode !) et allez dans l’onglet Status pour vérifier que le mode cluster est bien actif et que l’alerte email est bien appliquée dans la partie configuration.
Testons le bon fonctionnement des alertes en créant une règle prometheus fake et lancer kaf test-alert.yaml pour l’appliquer :
apiVersion: monitoring.coreos.com/v1kind: PrometheusRulemetadata: name: test-alert namespace: monitoring labels: app: kube-prometheus-stack release: prometheusspec: groups: - name: test.rules rules: - alert: TestCriticalAlert expr: vector(1) for: 1m labels: namespace: monitoring severity: critical annotations: summary: "Test alert for email notification"Après quelques instants, vous devriez voir l’alerte apparaître dans Prometheus, onglet Alerts, qui liste l’ensemble des règles Prometheus actives, avec un état Pending.

C’est le mode intermédiaire avant que l’alerte ne soit déclenchée, ce qui se produit lorsque la condition de la règle est vraie pendant toute la durée spécifiée dans le champ for. Dans notre cas, la condition est toujours juste puisque l’expression vector(1) renvoie toujours 1, et la durée est fixée à 1 minute.
Passé ce délai, l’alerte passera à l’état Firing.

Vous devriez la voir apparaître dans Alertmanager, groupé dans monitoring/email/email-notifications, confirmant que l’alerte est bien passé dans la bonne route et le bon receiver.
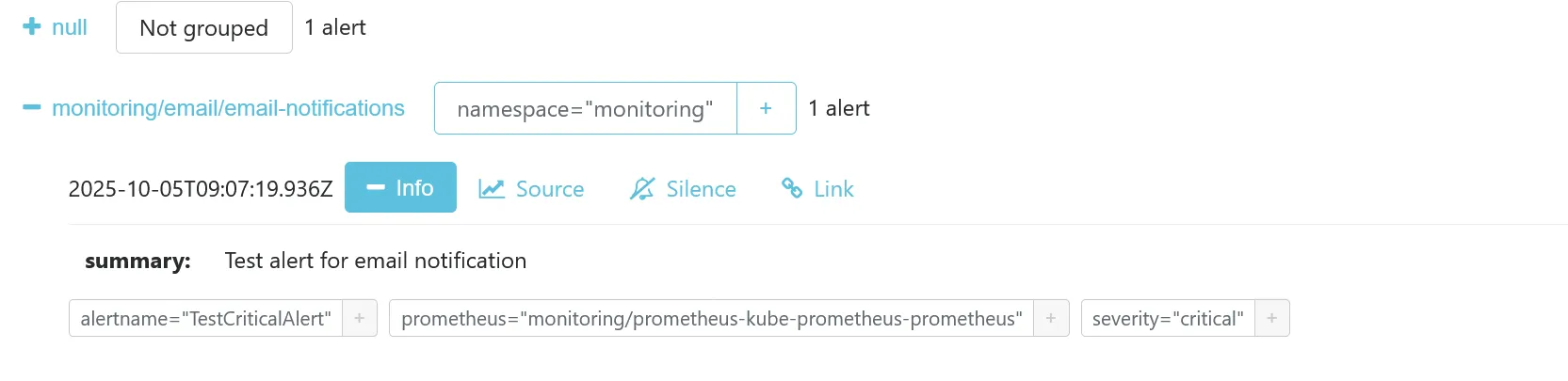
Si votre SMTP est bien configuré, vous devriez recevoir un email d’alerte dans votre boîte de réception, avec les bonnes URLs configurées, grâce aux paramètres externalUrl.
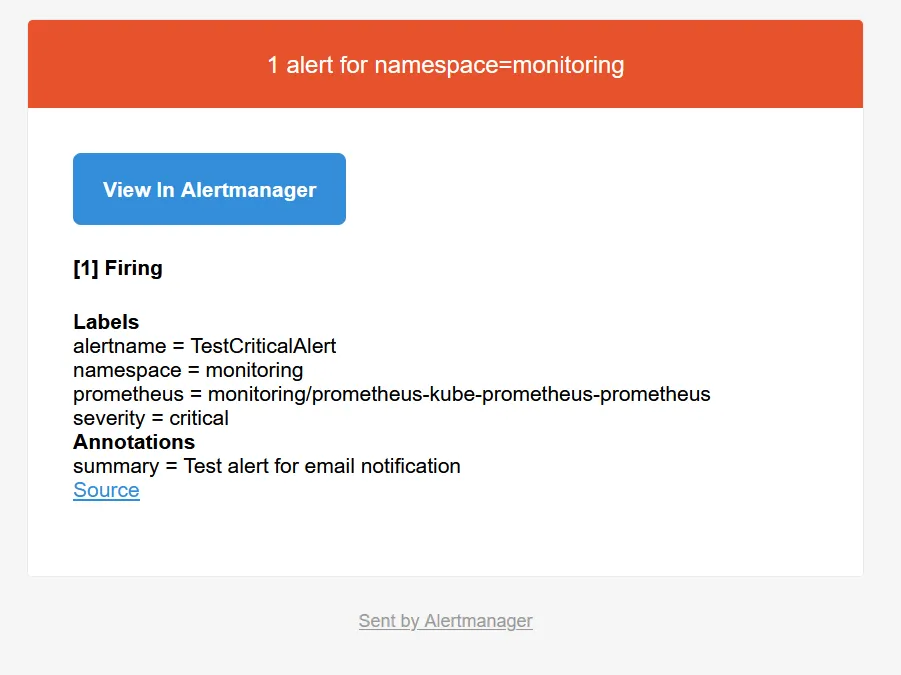
Supprimer l’alerte fake via kdel -f test-alert.yaml.
Dashboard 📈
Bien que Prometheus fournisse des fonctionnalités pour la visualisation des métriques, cela reste pour une utilisation avancée nécessitant des connaissances en PromQL. Pour une expérience plus riche et interactive, nous allons installer Grafana, l’outil dataviz de prédilection pour la visualisation de tous types de métriques.
Bien que Grafana soit inclus dans le chart kube-prometheus-stack (en tant que subchart), ce dernier est de base extrêmement lourd à installer et à configurer, et y inclure Grafana ne ferait que nous faire perdre notre temps. Je préfère donc le gérer séparément pour plus de flexibilité en termes de mise à jour.
module "kube_monitoring" { // ...
grafana_smtp_username = var.grafana_smtp_username grafana_smtp_password = var.grafana_smtp_password grafana_from = "grafana.dev@ohmytalos.io"
grafana_dashboards = { traefik = { gnetId = 17347 revision = 9 }, longhorn = { gnetId = 16888 revision = 9 }, crowdsec = { url = "https://raw.githubusercontent.com/crowdsecurity/grafana-dashboards/master/dashboards_v5/Crowdsec%20Overview.json" datasource = "prometheus" } }}Explanation
Rien de bien particulier à part la configuration du SMTP pour l’envoi de notifications par email.
Nous rajoutons quelques dashboards additionnels pour Traefik, Longhorn, et Crowdsec. Libre à vous d’en ajouter d’autres selon vos besoins. Les ids et les révisions peuvent être récupérés sur le site de Grafana Labs.
// ...
variable "grafana_smtp_username" { type = string}
variable "grafana_smtp_password" { type = string sensitive = true}fnox set TF_VAR_grafana_smtp_username "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_grafana_smtp_password "xxxxxxxxxxxxxxxxxxxxx" --provider age// ...
variable "grafana_smtp_username" { description = "The SMTP username for Grafana" type = string}
variable "grafana_smtp_password" { description = "The SMTP password for Grafana" type = string sensitive = true}
variable "grafana_from" { description = "The email address to send Grafana notifications from" type = string}
variable "grafana_dashboards" { description = "Additional Grafana dashboards" type = map(object({ gnetId = optional(number) revision = optional(number) url = optional(string) datasource = optional(string) })) default = {}}resource "kubernetes_namespace_v1" "grafana" { metadata { name = "grafana" }}
resource "kubernetes_secret_v1" "grafana_smtp" { metadata { name = "grafana-smtp" namespace = kubernetes_namespace_v1.grafana.metadata[0].name }
data = { user = var.grafana_smtp_username password = var.grafana_smtp_password }}
resource "helm_release" "grafana" { repository = "oci://ghcr.io/grafana-community/helm-charts" chart = "grafana" version = "12.2.1"
name = "grafana" namespace = kubernetes_namespace_v1.grafana.metadata[0].name max_history = 2
set = concat([ { name = "smtp.existingSecret" value = kubernetes_secret_v1.grafana_smtp.metadata[0].name }, { name = "grafana\\.ini.smtp.enabled" value = "true" }, { name = "grafana\\.ini.smtp.host" value = var.smtp_host }, { name = "grafana\\.ini.smtp.from_address" value = var.grafana_from }, { name = "grafana\\.ini.server.domain" value = "grafana.${var.internal_domain}" }, { name = "persistence.enabled" value = "true" }, { name = "persistence.storageClassName" value = "longhorn-crypto" }, { name = "persistence.size" value = "2Gi" }, { name = "sidecar.dashboards.searchNamespace" value = "ALL" }, { name = "sidecar.datasources.searchNamespace" value = "ALL" }, { name = "deploymentStrategy.type" value = "Recreate" }, { name = "serviceMonitor.enabled" value = "true" }, { name = "sidecar.alerts.enabled" value = "true" }, { name = "sidecar.dashboards.enabled" value = "true" }, { name = "sidecar.datasources.enabled" value = "true" }, ], flatten([ for service, attrs in var.grafana_dashboards : [ for key, value in attrs : { name = "dashboards.default.${service}.${key}" value = value } ] ]))
values = [yamlencode({ dashboardProviders = { "dashboardproviders.yaml" = { apiVersion = 1 providers = [ { name = "default" orgId = 1 folder = "" type = "file" disableDeletion = false editable = false options = { path = "/var/lib/grafana/dashboards/default" } } ] } } })]}
resource "kubernetes_manifest" "traefik_ingress_route_grafana" { manifest = { apiVersion = "traefik.io/v1alpha1" kind = "IngressRoute" metadata = { name = "grafana" namespace = kubernetes_namespace_v1.grafana.metadata[0].name } spec = { entryPoints = ["internal"] routes = [ { match = "Host(`grafana.${var.internal_domain}`)" kind = "Rule" services = [ { name = "grafana" port = "service" } ] } ] } }}Explanation
Niveau persistance rien de spécial, on reste sur un simple Deployment à replica unique, un simple longhorn-crypto suffit.
La configuration principale de Grafana passe par grafana.ini, que l’on utilise notamment pour la section SMTP.
La particularité de chaque Pod d’instance Grafana est d’inclure tout un tas de sidecars tous en charge de monter et fournir automatiquement dans Grafana divers types de ressources à partir de ConfigMap :
- Un sidecar pour les dashboards.
- Un sidecar pour les datasources, utilisés pour se connecter à divers backend tel que Prometheus, Loki, Tempo, etc.
- Un sidecar pour les alertes. Pas de rapport avec
Alertmanager, il s’agit d’alertes propres à Grafana, qui peuvent être complémentaires. Adapté pour des alertes secondaires avec une UI simple pour les créer. Pour les principales alertes infra, il vaut mieux privilégierAlertmanager, dédié pour cela et bien plus léger et résilient.
Nous activons tous les sidecars et configurons leur searchNamespace à ALL pour qu’ils puissent détecter les ConfigMap dans tous les namespaces.
Enfin le Pod du chart inclus un init conteneur download-dashboards qui permet de télécharger des dashboards depuis des référentiels distants avant démarrage du conteneur. Ceci nous évite de se trimballer avec des gros ConfigMap de json dashboards localement.
C’est ce conteneur qui téléchargera nos dashboards définis en amont. Ils seront inclus dans le fichier monté localement /var/lib/grafana/dashboards/default (selon la clé choisie). Il reste donc à définir dans dashboardProviders la source de ce fichier pour que l’import soit effectif.
Dans le ingress pas besoin de rajouter l’authentification, Grafana étant déjà protégé par son propre système d’authentification.
On déploie comme d’habitude et aller sur https://grafana.dev.ohmytalos.io et loguez-vous via le compte admin. Utiliser kgsec -n grafana -o yaml grafana | yq -r '.data."admin-password"' | base64 -d pour récupérer le mot de passe admin autogénéré. Allez dans la section dashboards :
Vous y trouverez plein de dashboards déjà inclus :
- Ceux de Kubernetes, fournis par le chart
kube-prometheus-stack. - Ceux de
Cilium, qui inclus ses propres charts - Ceux de
CloudNativePG - Ceux additionnels téléchargés via le sidecar
download-dashboards.
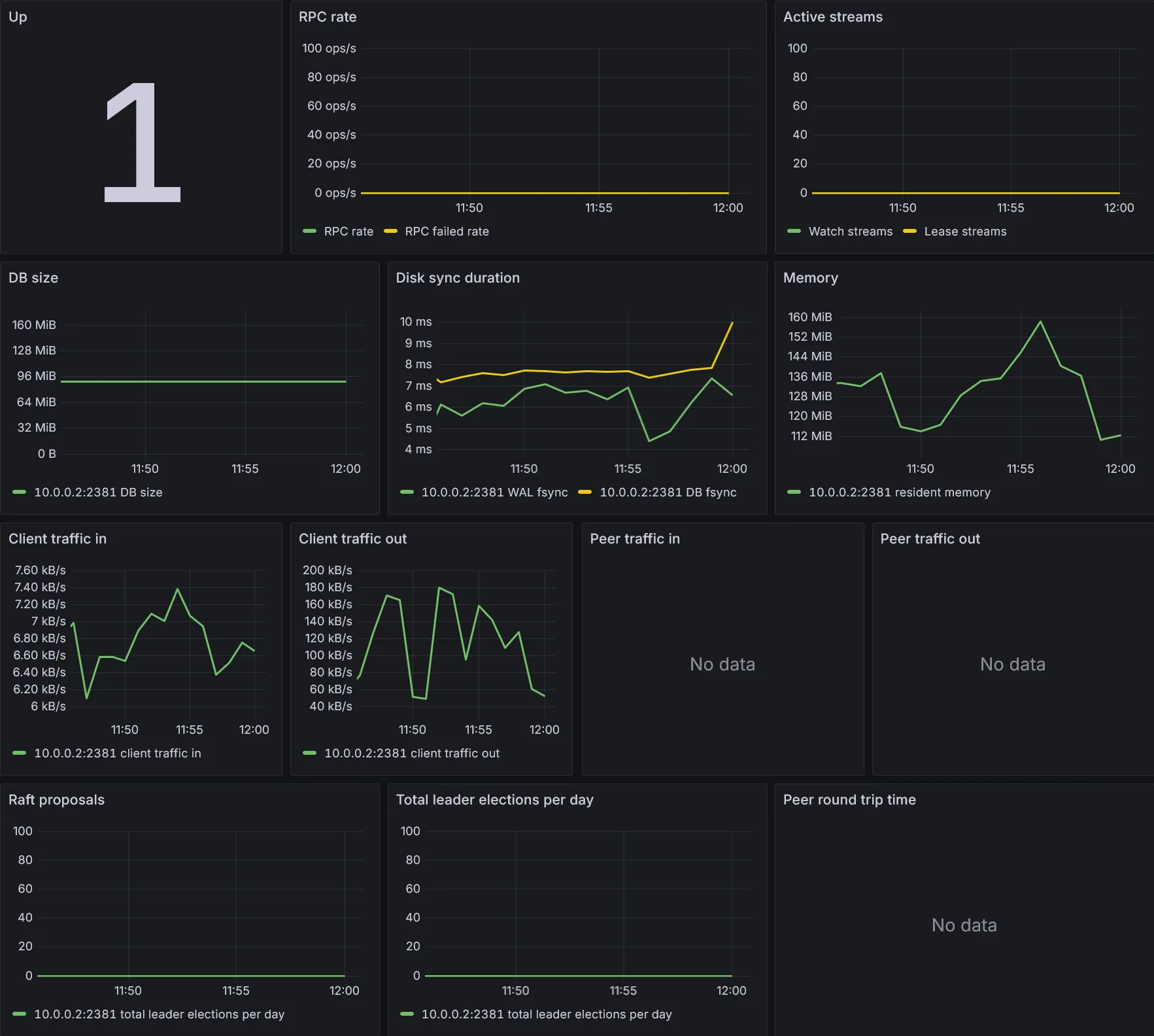
Dashboards Kubernetes
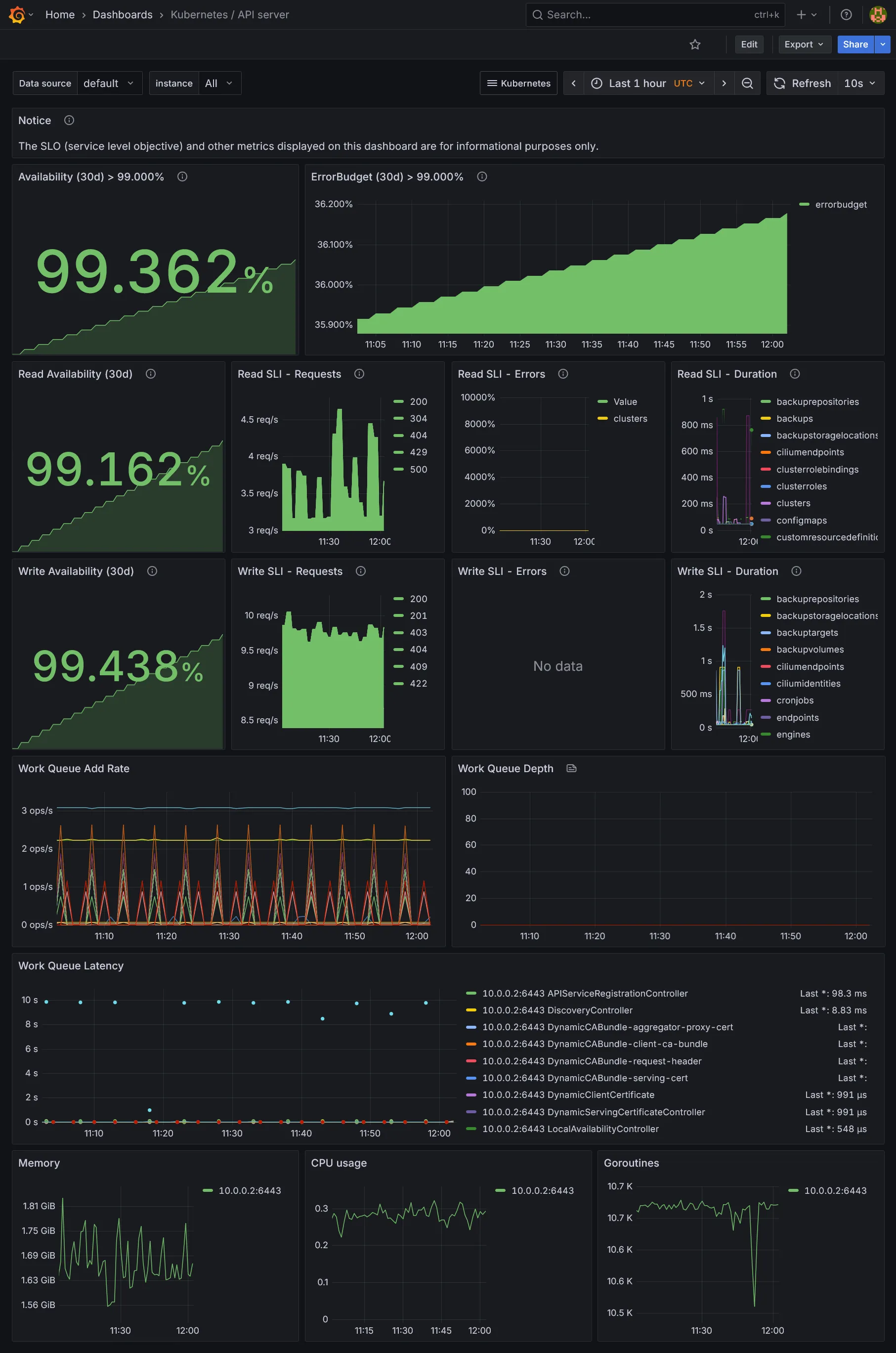
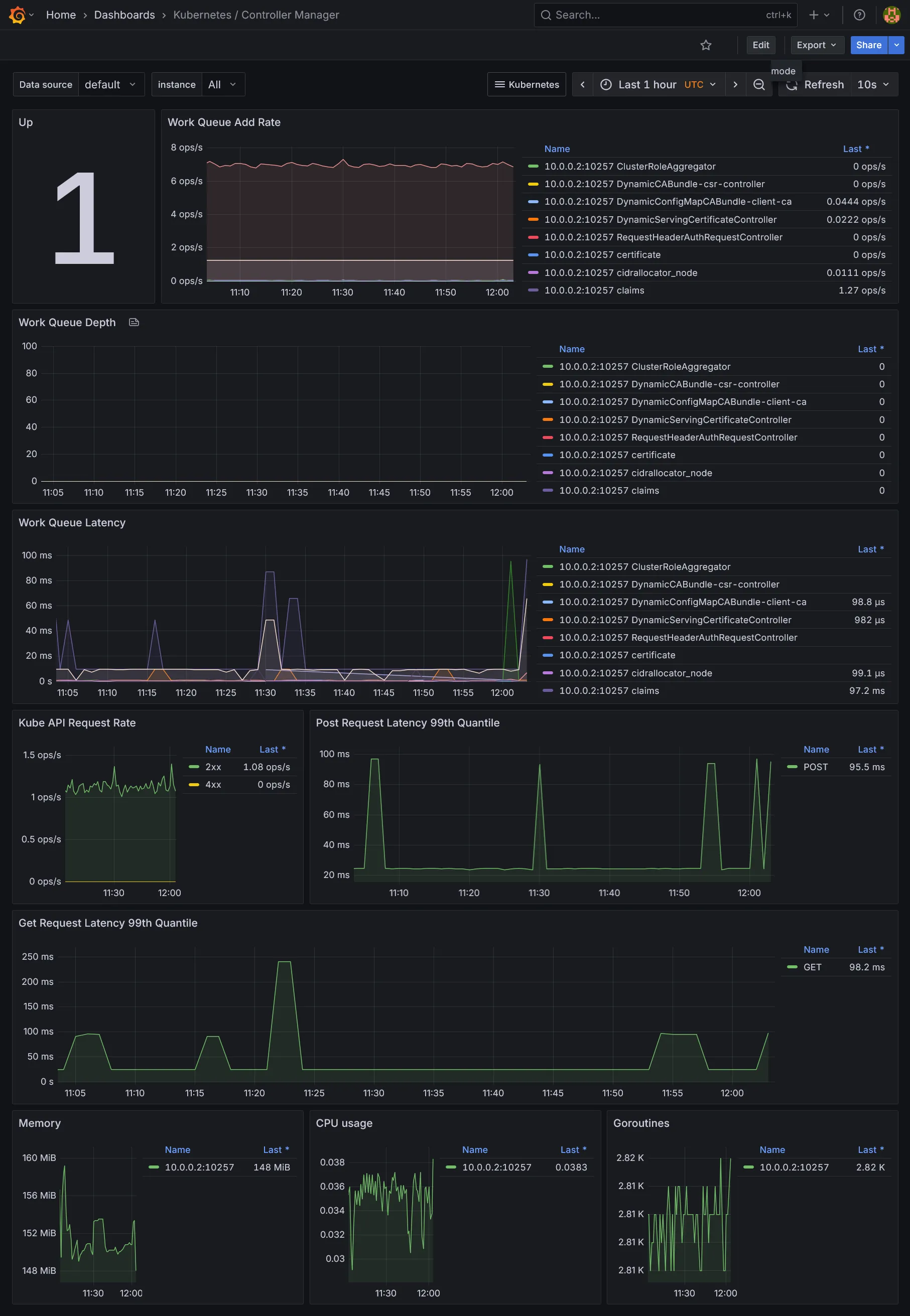
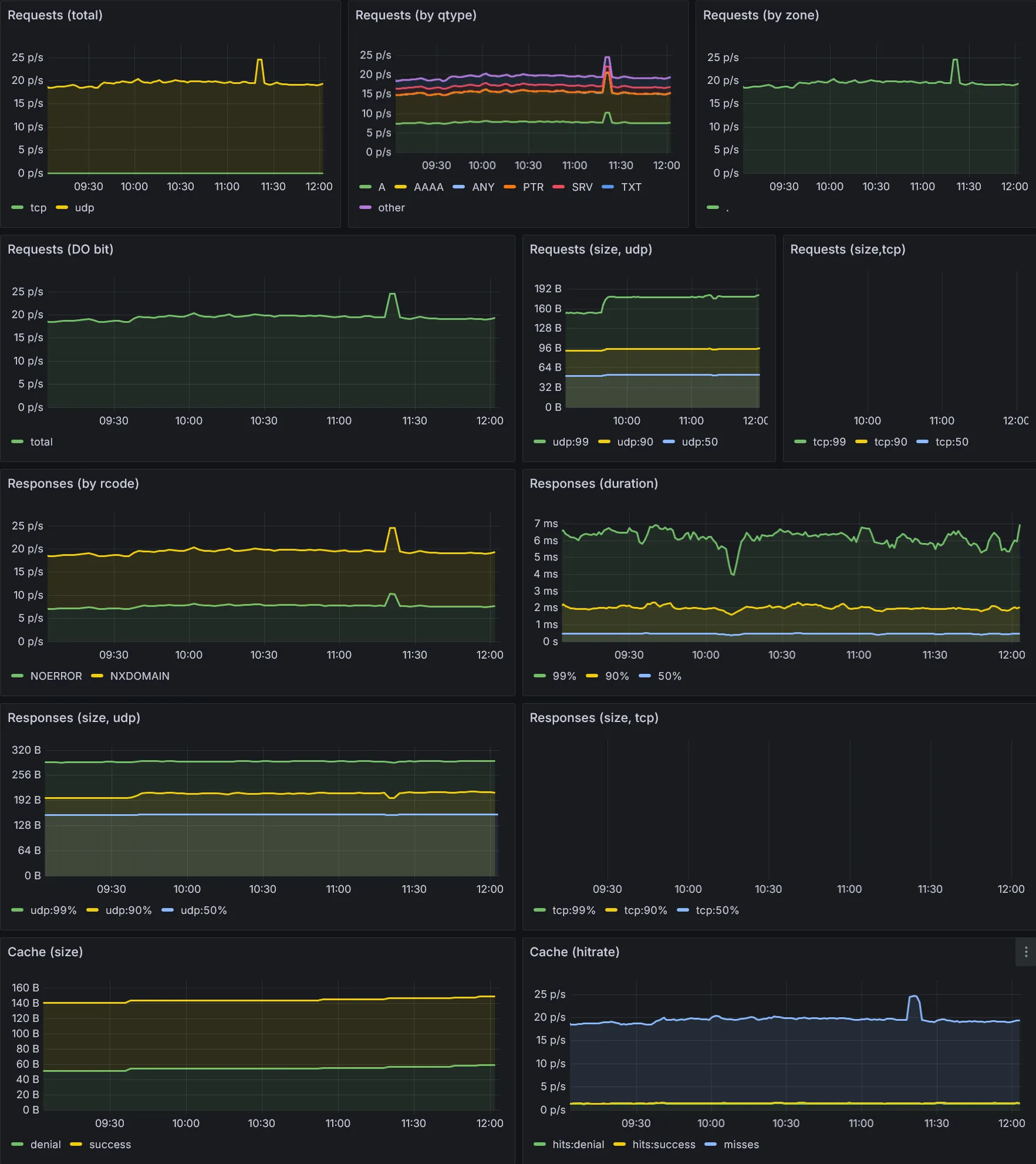
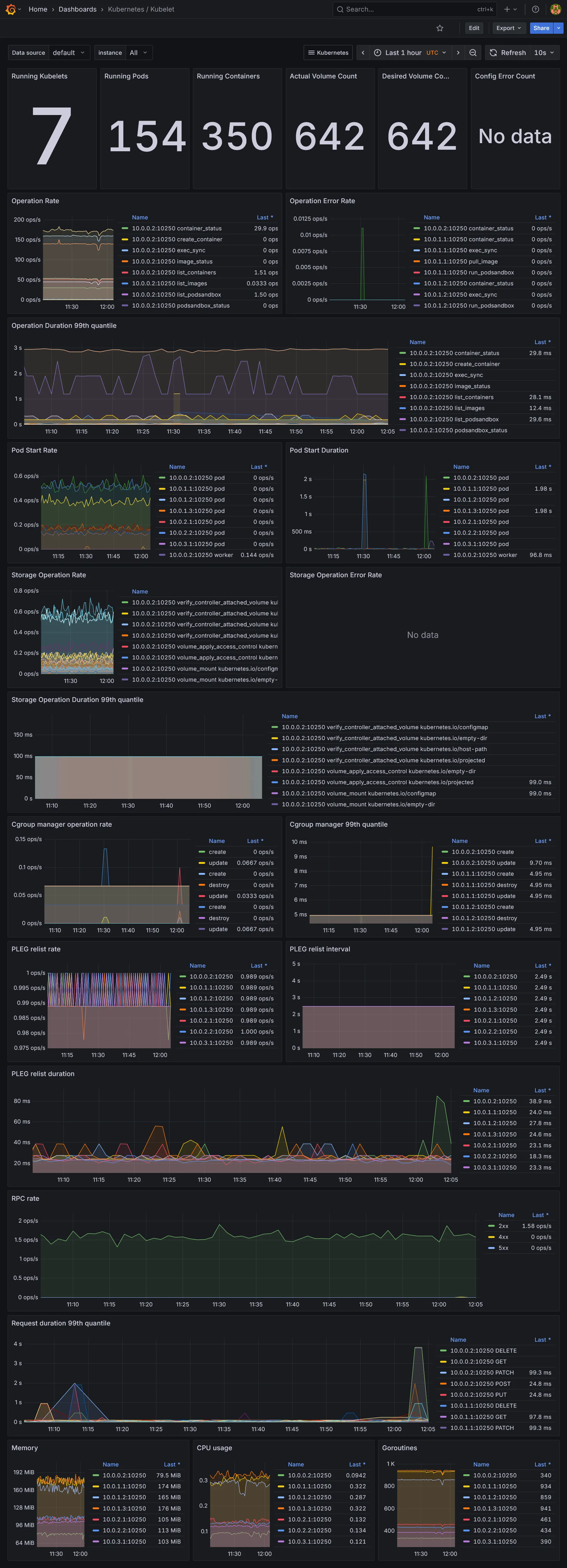
Dashboards Ressources
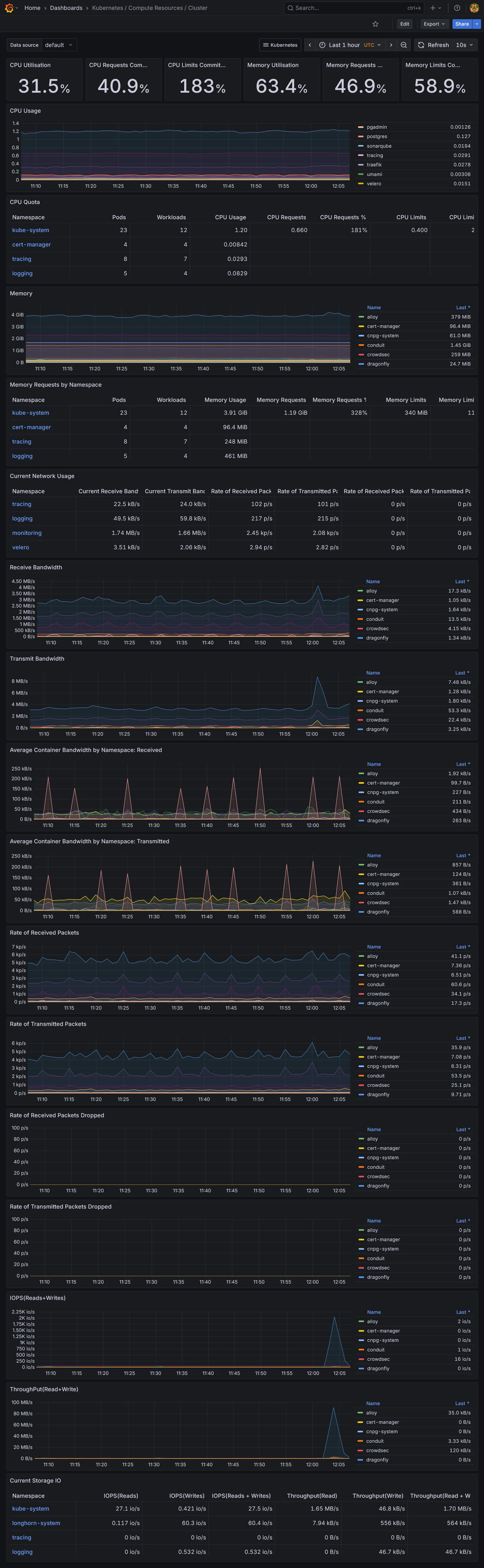
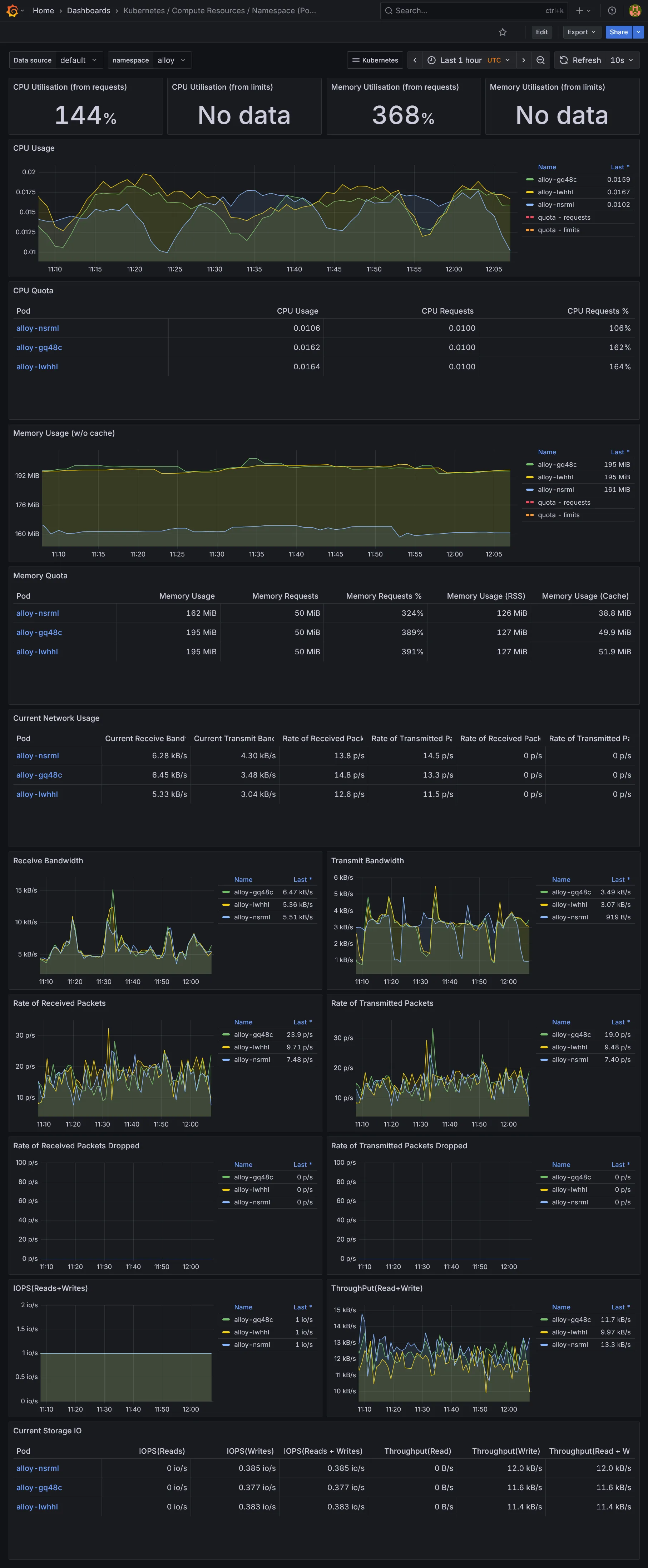
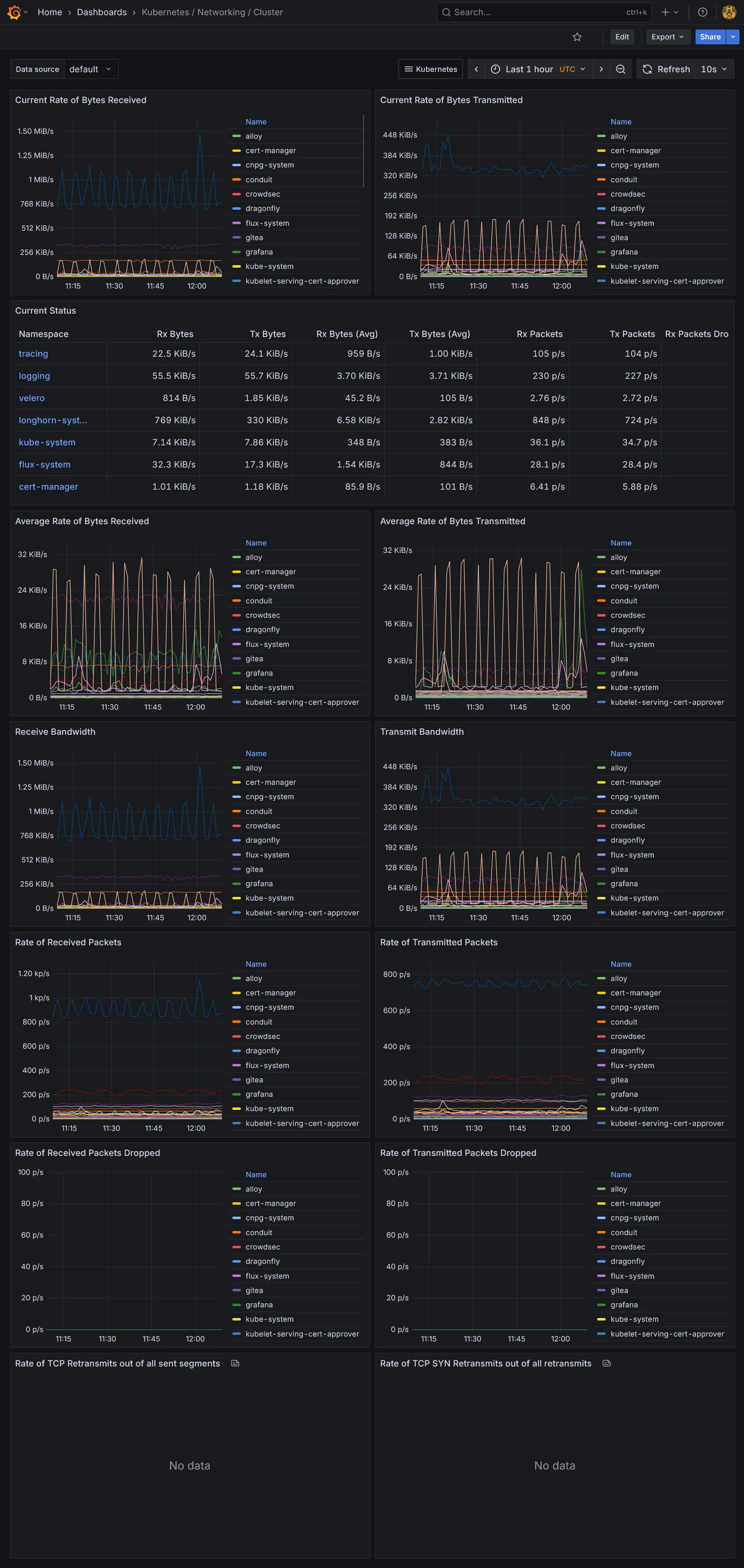
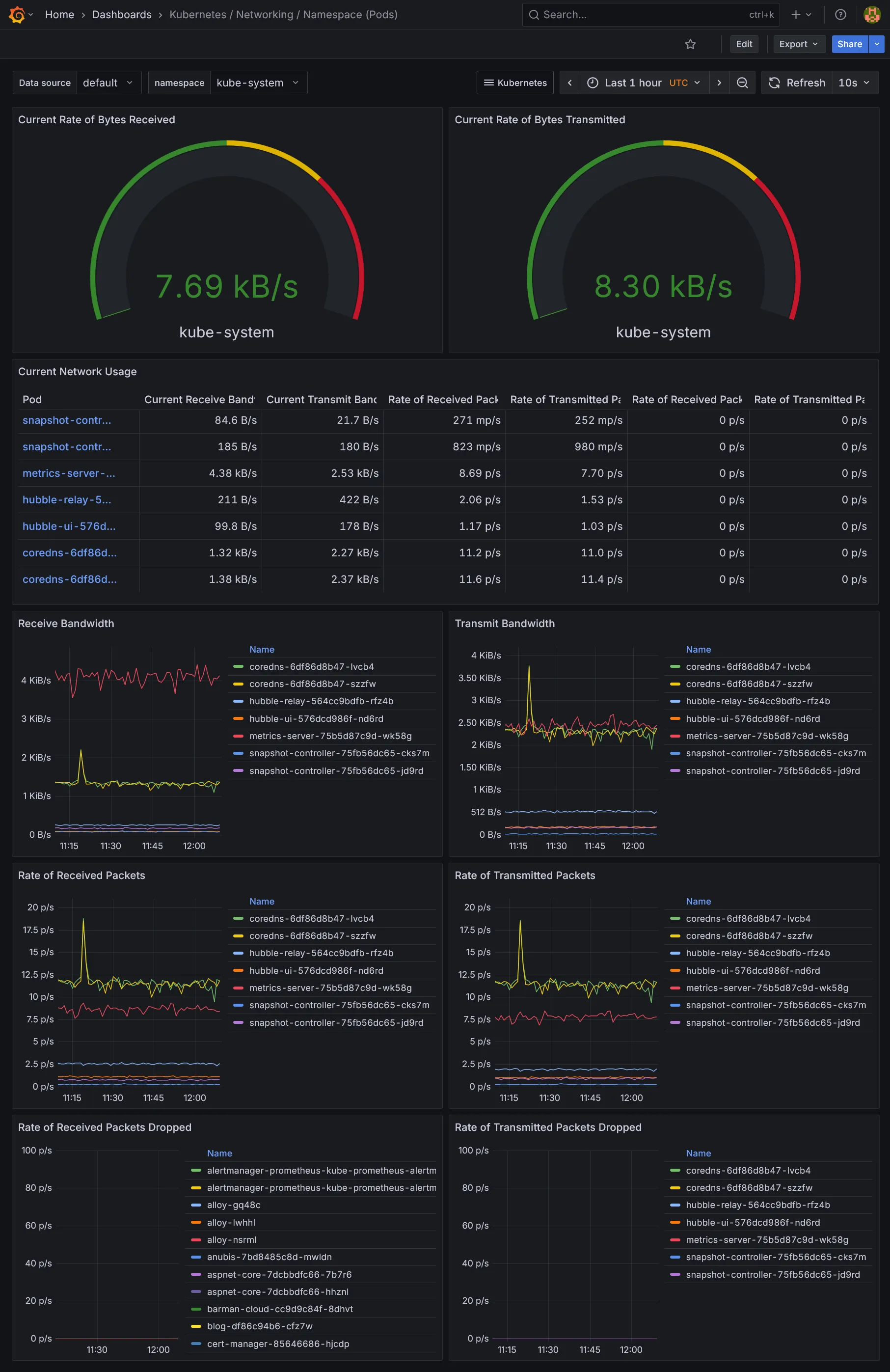
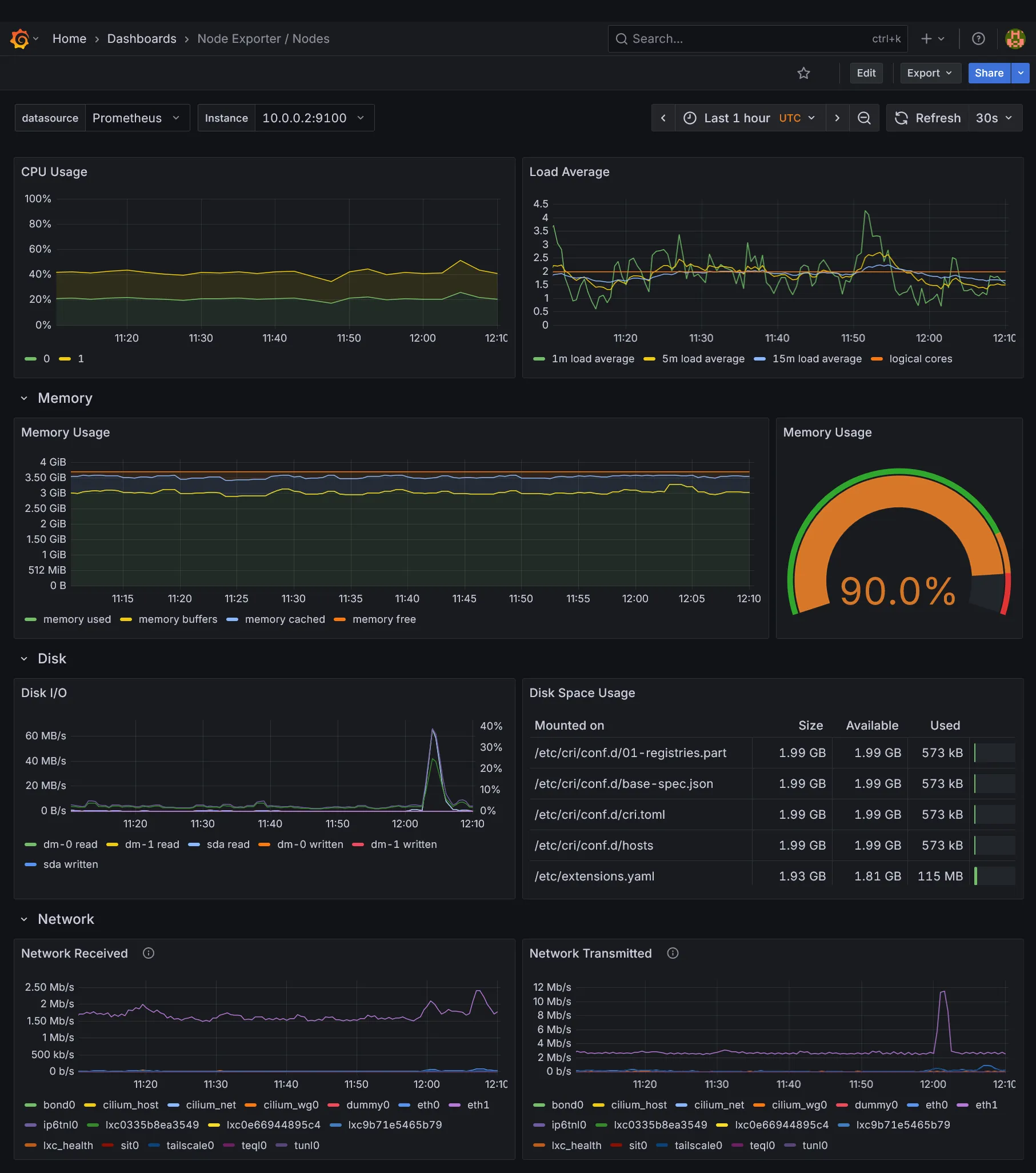
Dashboards additionnels
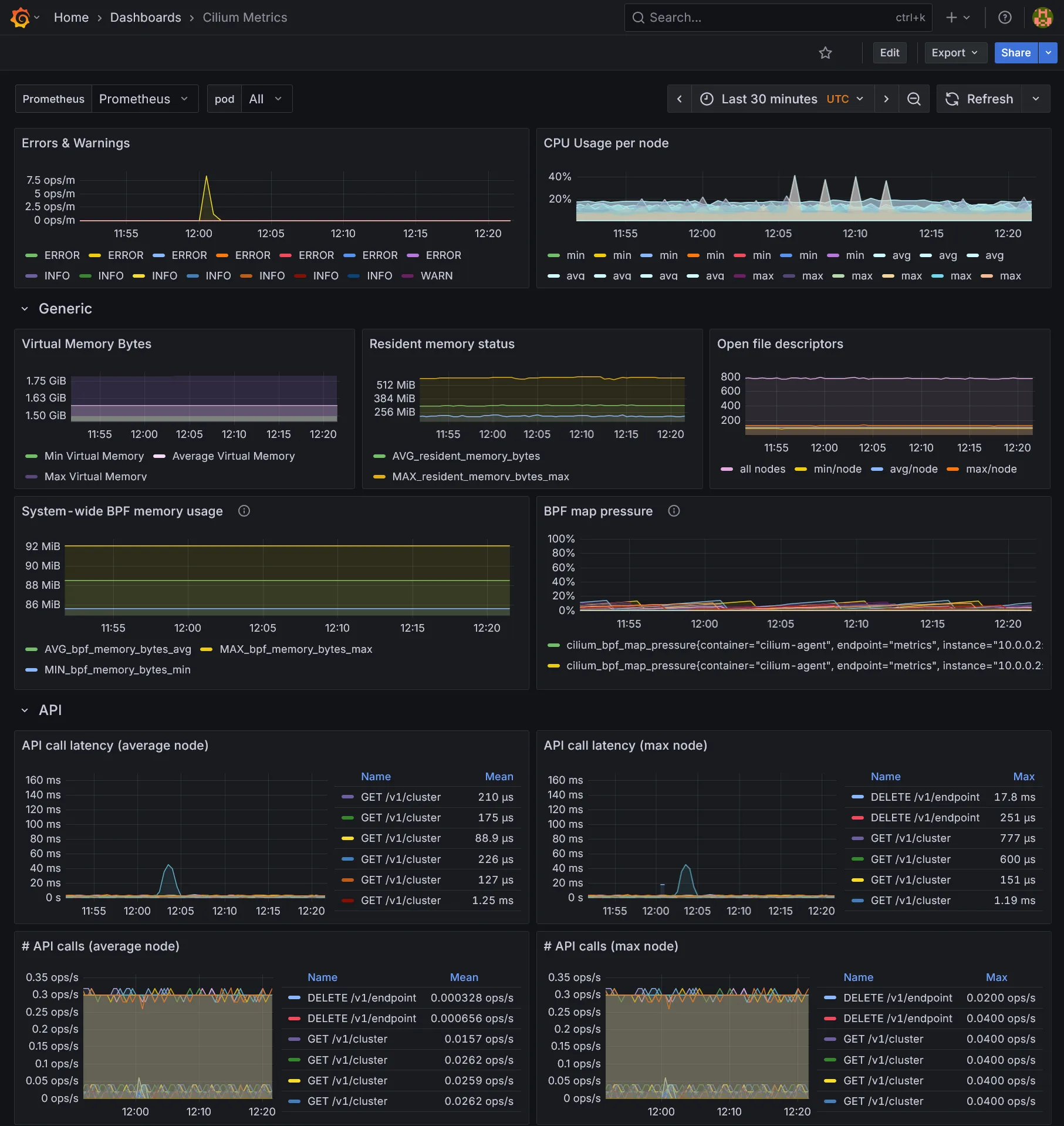
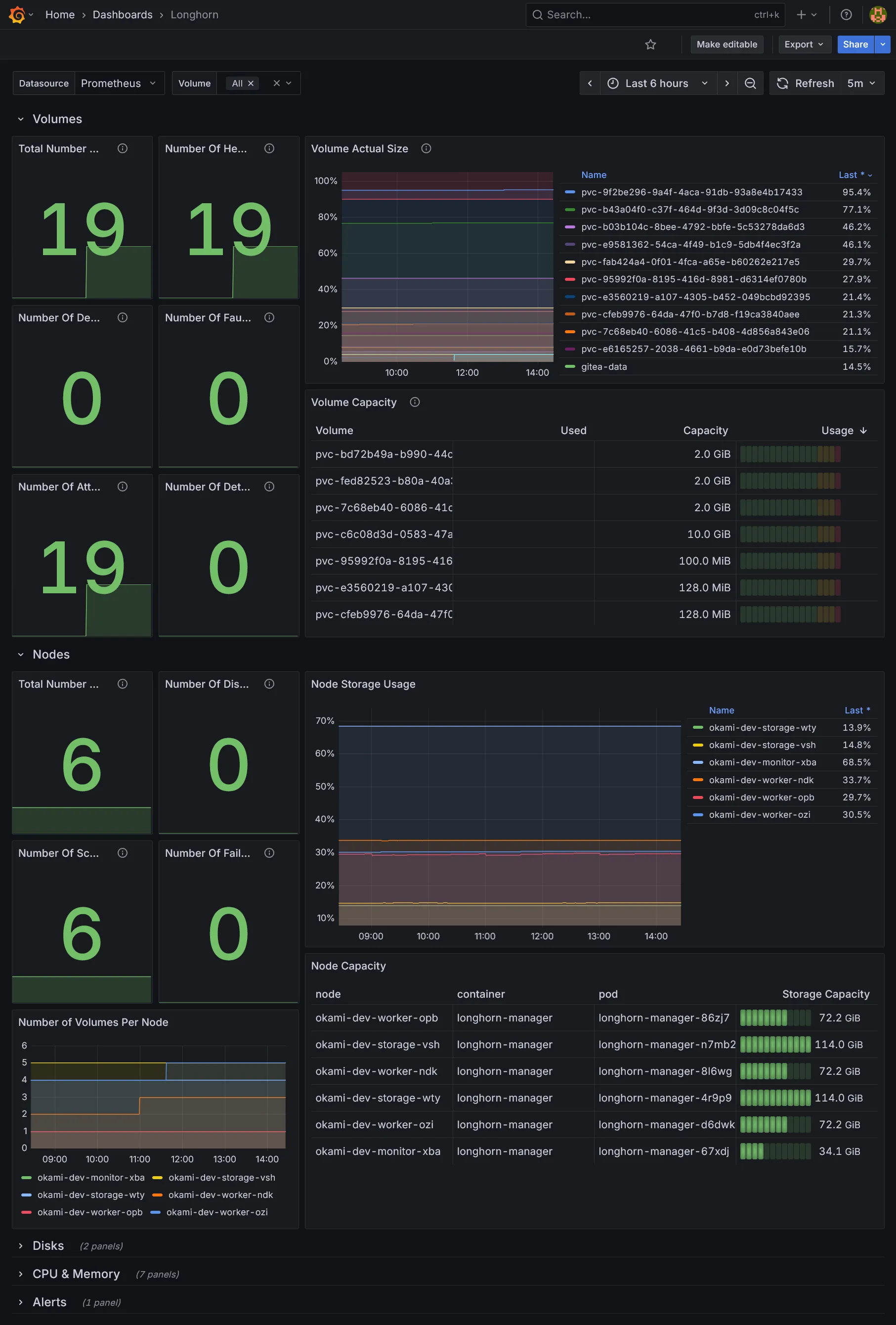
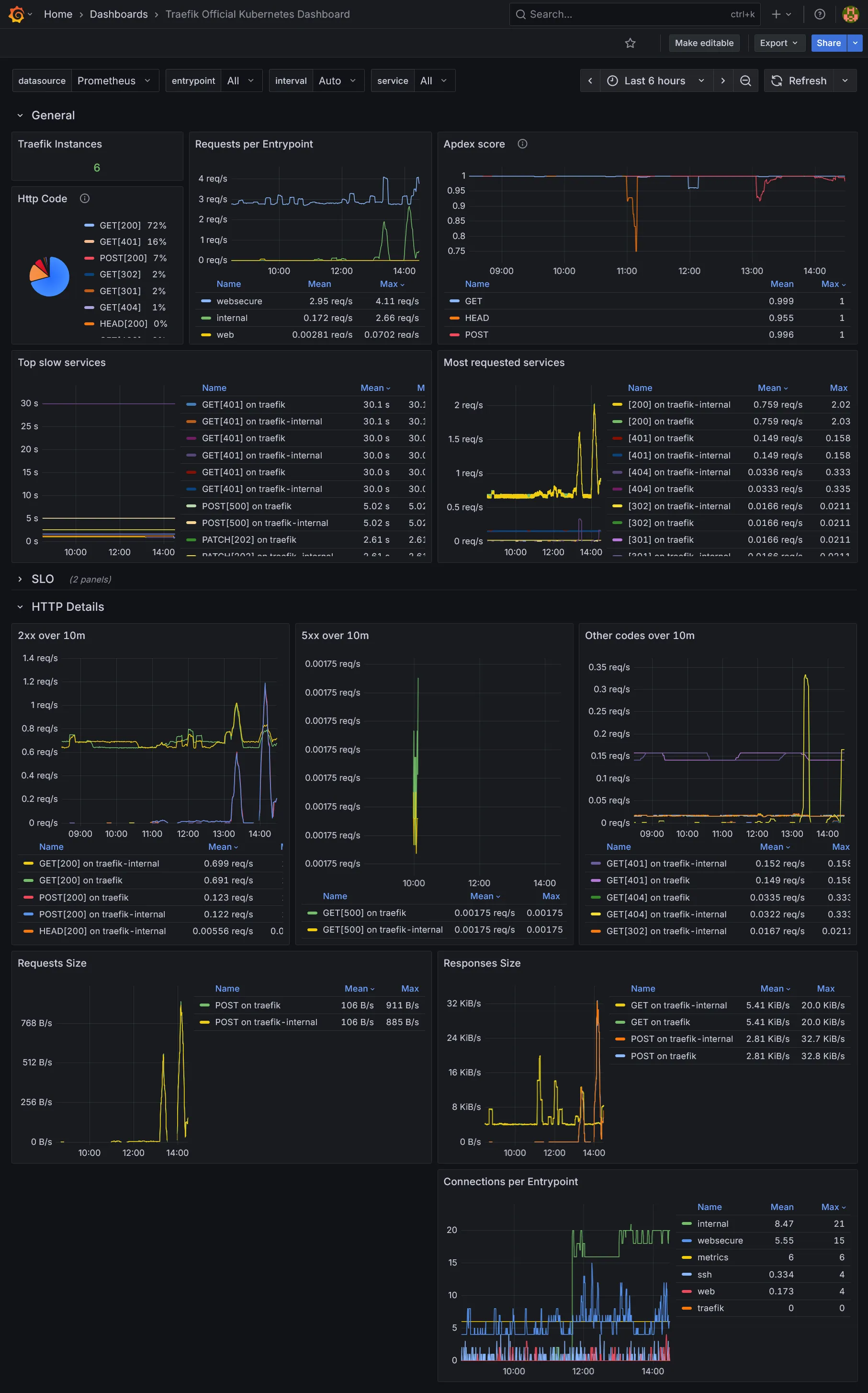
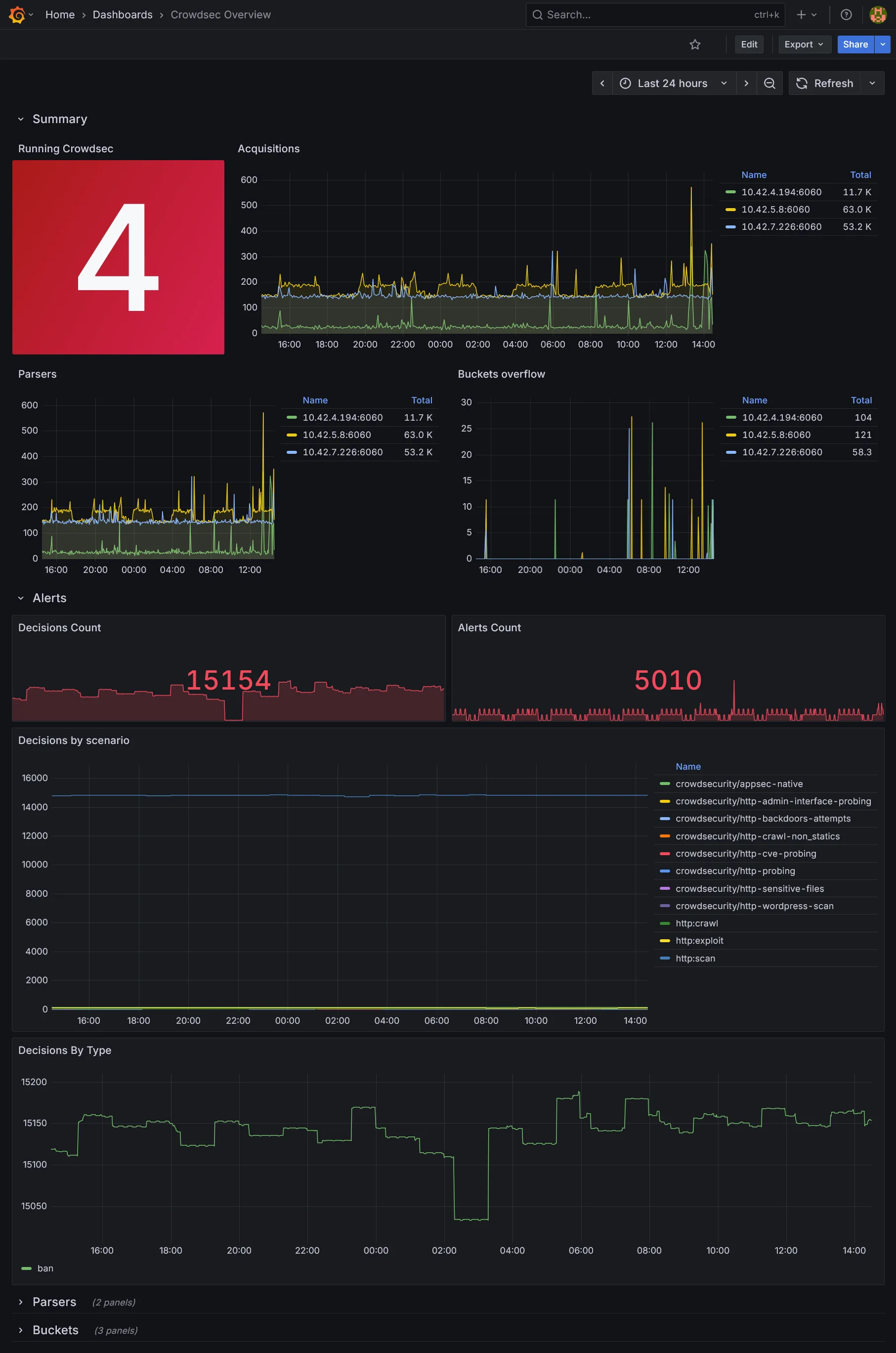
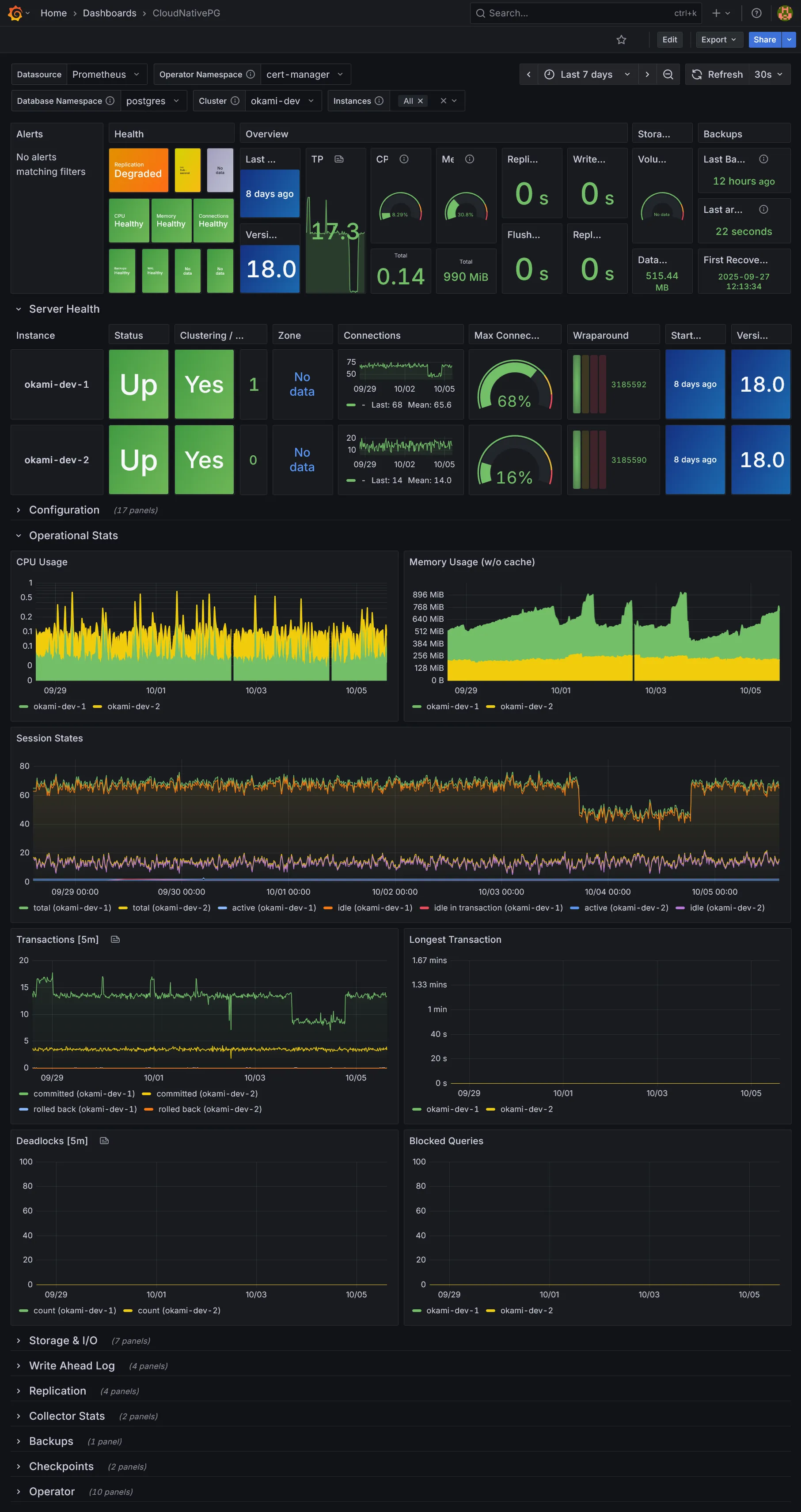
Conclusion
Nous voilà déjà avec tout plein de dashboards. La partie métrique et dataviz étant vue, il nous reste la collecte des logs et traces, des données assez massives à collecter. Suite dans la section suivante.