
Objectif 🎯
Nous avons vu la partie métrique précédemment, et il est temps de s’attaquer au logging et à la traçabilité. Nous allons commencer par installer les backends de stockage Loki pour les logs et Tempo pour les traces, puis nous verrons comment collecter efficacement ces données avec Alloy.
Voici le résultat attendu en terme d’architecture de la stack de télémétrie, en excluant la partie métrique déjà vue :

Backends de stockage 🗄️
Logging 📇
module "kube_monitoring" { source = "../../modules/kube/monitoring"
loki_s3_endpoint = "https://${local.s3_endpoint}" loki_s3_region = local.s3_region loki_s3_bucket = local.cluster_name loki_s3_access_key = var.loki_s3_username loki_s3_secret_key = var.loki_s3_password}Explanation
Pour le stockage des logs long terme, Loki a besoin d’un stockage S3.
// ...
variable "loki_s3_username" { type = string}
variable "loki_s3_password" { type = string sensitive = true}fnox set TF_VAR_loki_s3_username "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_loki_s3_password "xxxxxxxxxxxxxxxxxxxxx" --provider age// ...
variable "loki_s3_endpoint" { description = "The endpoint of the S3 compatible storage" type = string}
variable "loki_s3_access_key" { description = "The access key for the S3 compatible storage" type = string}
variable "loki_s3_secret_key" { description = "The secret key for the S3 compatible storage" type = string sensitive = true}
variable "loki_s3_region" { description = "The region of the S3 compatible storage" type = string}
variable "loki_s3_bucket" { description = "The bucket of the S3 compatible storage" type = string}
variable "loki_retention_period" { type = string default = "744h"}resource "kubernetes_namespace_v1" "logging" { metadata { name = "logging" labels = { "pod-security.kubernetes.io/enforce" = "privileged" } }}
resource "helm_release" "loki" { repository = "oci://ghcr.io/grafana-community/helm-charts" chart = "loki" version = "13.3.1"
name = "loki" namespace = kubernetes_namespace_v1.logging.metadata[0].name max_history = 2
set = [ { name = "loki.storage.bucketNames.chunks" value = var.loki_s3_bucket }, { name = "loki.storage.bucketNames.ruler" value = var.loki_s3_bucket }, { name = "loki.storage.bucketNames.admin" value = var.loki_s3_bucket }, { name = "loki.storage.s3.endpoint" value = var.loki_s3_endpoint }, { name = "loki.storage.s3.region" value = var.loki_s3_region }, { name = "loki.storage.s3.accessKeyId" value = var.loki_s3_access_key }, { name = "chunksCache.allocatedMemory" value = 512 }, { name = "resultsCache.allocatedMemory" value = 256 }, { name = "lokiCanary.enabled" value = "false" }, { name = "test.enabled" value = "false" }, { name = "monitoring.dashboards.enabled" value = "true" }, { name = "monitoring.serviceMonitor.enabled" value = "true" }, { name = "singleBinary.replicas" value = "2" }, { name = "read.replicas" value = "0" }, { name = "backend.replicas" value = "0" }, { name = "write.replicas" value = "0" }, { name = "singleBinary.persistence.storageClass" value = "longhorn-crypto" }, { name = "singleBinary.persistence.size" value = "2Gi" }, { name = "singleBinary.tolerations[0].key" value = "node-role.kubernetes.io/storage" }, { name = "singleBinary.tolerations[0].operator" value = "Exists" }, { name = "singleBinary.nodeSelector.node\\.kubernetes\\.io/role" value = "storage" } ]
set_sensitive = [ { name = "loki.storage.s3.secretAccessKey" value = var.loki_s3_secret_key } ]
values = [ yamlencode({ loki = { structuredConfig = { auth_enabled = false limits_config = { retention_period = var.loki_retention_period } compactor = { retention_enabled = true delete_request_store = "s3" } storage_config = { object_prefix = "loki" } ingester_client = { remote_timeout = "10s" } analytics = { reporting_enabled = false } schema_config = { configs = [ { from = "2024-01-01" store = "tsdb" object_store = "s3" schema = "v13" index = { prefix = "index_" period = "24h" } } ] } } } }) ]}
resource "kubernetes_config_map_v1" "grafana_datasource_loki" { metadata { name = "grafana-datasource-loki" namespace = kubernetes_namespace_v1.logging.metadata[0].name labels = { grafana_datasource = "1" } }
data = { "datasource.yaml" = yamlencode({ apiVersion = 1 datasources = [ { name = "Loki" type = "loki" uid = "loki" url = "http://loki-gateway.logging" access = "proxy" jsonData = { derivedFields = [ { name = "TraceId" datasourceName = "Tempo" datasourceUid = "tempo" matcherRegex = "TraceId" matcherType = "label" url = "$$${__value.raw}" }, { name = "trace_id" datasourceName = "Tempo" datasourceUid = "tempo" matcherRegex = "trace_id" matcherType = "label" url = "$$${__value.raw}" } ] } } ] }) }}Explanation
De la belle config helm bien velue qu’on aime bien…
Loki sera installé en mode monolithique avec un seul composant singleBinary en 2 réplicas placés sur les nœuds de storage, largement suffisant au regard de la dimension actuelle du cluster. Le mode singleBinary intègre :
- Le composant
writepour l’ingestion des logs - Un composant
readpour la gestion des requêtes de lecture via le language LogQL - Un composant
backendpour la gestion des logs long-terme sur le s3.
Loki fourni également 2 composants de memcached pour le caching des chunks et des résultats de requêtes, que l’on configure à 512Mo et 256Mo respectivement. Ceci permet d’optimiser au mieux les performances de Loki en termes de gestion des flux de données.
Est inclus par ailleurs un composant canary pour le monitoring régulier de l’état de santé du cluster Loki. Je me permets de le désactiver, car il bourrine sévère.
La clé structuredConfig permet de passer une config Loki complète en YAML. On y active la rétention des logs, on désactive l’auth pour simplifier (à adapter à vos besoins), on configure le stockage S3.
Enfin, on configure le datasource Grafana pour Loki, pour une intégration automatique. La petite particularité supplémentaire est l’ajout de 2 derivedField pour permettre de faire le lien depuis les logs vers les futures traces dans Grafana. Le but est de récupérer la valeur du champ TraceId (traefik JSON) ou trace_id (logs OTLP) et de faire le lien vers la trace sur tempo.
Appliquer la config avec terraform apply. Vérifier que tout est bien déployé avec kgp -n logging.
Loki fourni son propre dashboard Grafana :
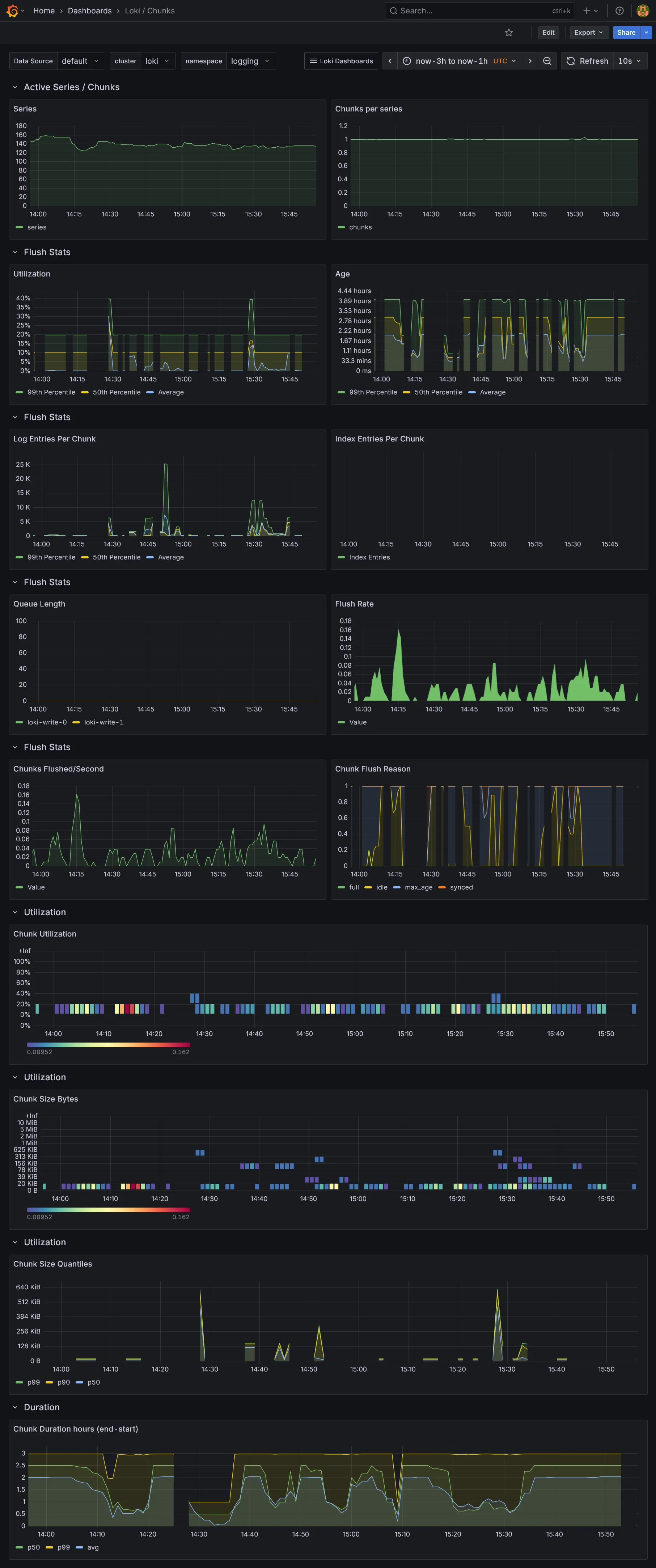
Mais il sera vide en l’état actuel, car nous n’avons aucun outil de collecte de données pour le moment. On enchaîne tout de suite sur l’installation du backend Tempo.
Traces 🔍
module "kube_monitoring" { // ...
tempo_s3_endpoint = local.s3_endpoint tempo_s3_region = local.s3_region tempo_s3_bucket = local.cluster_name tempo_s3_access_key = var.tempo_s3_username tempo_s3_secret_key = var.tempo_s3_password}Explanation
De même que pour Loki, nous restons sur le mode monolithique par défaut qui reste le plus adapté au regard de la petite taille de notre cluster. Cependant nous activons plusieurs replicas, ce qui nécessite un stockage S3.
// ...
variable "tempo_s3_username" { type = string}
variable "tempo_s3_password" { type = string sensitive = true}fnox set TF_VAR_tempo_s3_username "xxxxxxxxxxxxxxxxxxxxx" --provider agefnox set TF_VAR_tempo_s3_password "xxxxxxxxxxxxxxxxxxxxx" --provider age// ...
variable "tempo_s3_endpoint" { description = "The endpoint of the S3 compatible storage" type = string}
variable "tempo_s3_access_key" { description = "The access key for the S3 compatible storage" type = string}
variable "tempo_s3_secret_key" { description = "The secret key for the S3 compatible storage" type = string sensitive = true}
variable "tempo_s3_region" { description = "The region of the S3 compatible storage" type = string}
variable "tempo_s3_bucket" { description = "The bucket of the S3 compatible storage" type = string}resource "kubernetes_namespace_v1" "tracing" { metadata { name = "tracing" labels = { "pod-security.kubernetes.io/enforce" = "privileged" } }}
resource "helm_release" "tempo" { repository = "oci://ghcr.io/grafana-community/helm-charts" chart = "tempo" version = "2.0.0"
name = "tempo" namespace = kubernetes_namespace_v1.tracing.metadata[0].name max_history = 2
set = [ { name = "replicas" value = "2" }, { name = "persistence.enabled" value = "true" }, { name = "persistence.storageClassName" value = "longhorn-crypto-local" }, { name = "persistence.size" value = "2Gi" }, { name = "tolerations[0].key" value = "node-role.kubernetes.io/storage" }, { name = "tolerations[0].operator" value = "Exists" }, { name = "nodeSelector.node\\.kubernetes\\.io/role" value = "storage" }, { name = "tempo.storage.trace.backend" value = "s3" }, { name = "tempo.storage.trace.s3.bucket" value = var.tempo_s3_bucket }, { name = "tempo.storage.trace.s3.prefix" value = "tempo" }, { name = "tempo.storage.trace.s3.endpoint" value = var.tempo_s3_endpoint }, { name = "tempo.storage.trace.s3.region" value = var.tempo_s3_region }, { name = "tempo.storage.trace.s3.access_key" value = var.tempo_s3_access_key }, { name = "tempo.metricsGenerator.enabled" value = "true" }, { name = "tempo.metricsGenerator.remoteWriteUrl" value = "http://prometheus-operated.monitoring:9090/api/v1/write" } ]
set_sensitive = [ { name = "tempo.storage.trace.s3.secret_key" value = var.tempo_s3_secret_key } ]
set_list = [ { name = "tempo.overrides.defaults.metrics_generator.processors" value = [ "service-graphs", "span-metrics", "local-blocks" ] } ]}
resource "kubernetes_config_map_v1" "grafana_datasource_tempo" { metadata { name = "grafana-datasource-tempo" namespace = kubernetes_namespace_v1.tracing.metadata[0].name labels = { grafana_datasource = "1" } }
data = { "datasource.yaml" = yamlencode({ apiVersion = 1 datasources = [ { name = "Tempo" type = "tempo" uid = "tempo" url = "http://tempo.tracing:3200" access = "proxy" jsonData = { tracesToLogsV2 = { datasourceUid = "loki" filterByTraceID = true filterBySpanID = true spanEndTimeShift = "5s" spanStartTimeShift = "-5s" } tracesToMetrics = { datasourceUid = "prometheus" queries = [ { "name" : "Request rate", "query" : "sum by (client,server)(rate(traces_service_graph_request_total{$$__tags}[$$__rate_interval]))" }, { "name" : "Error rate", "query" : "sum by (client,server)(rate(traces_service_graph_request_failed_total{$$__tags}[$$__rate_interval]))" } ], tags = [ { key = "service.name", value = "server" } ] } serviceMap = { datasourceUid = "prometheus" } nodeGraph = { enabled = true } } } ] }) }}Explanation
Activer les ports de OpenTelemetry (OTLP) HTTP et gRPC pour la collecte des traces, puis paramétrer le stockage S3.
De même que pour les writers loki, on place les ingesters sur les nœuds de storage en 2 réplicas pour la haute dispo.
Nous activons metricsGenerator. C’est un composant spécifique indispensable pour permettre de faire le lien entre les traces et les métriques Prometheus. Nous le branchons sur le Prometheus déjà déployé dans le cluster grâce au write receiver déjà activé dans la section précédente. Nous activons les processors service-graphs, span-metrics et local-blocks. L’usage de ce dernier processor est nécessaire pour la visualisation des traces sous le menu menu Drilldown dans Grafana.
Enfin nous activons le datasource Grafana pour Tempo, avec la configuration des tracesToLogsV2 pour créer un lien depuis les traces vers les logs dans Grafana (le sens inverse de la datasource Loki). On précise une marge de 5 secondes avant et après le timestamp de chaque trace ou span pour avoir une vue plus complète des logs associés.
Le paramètre tracesToMetrics permet de créer un ou plusieurs liens, toujours depuis les traces vers des métriques Prometheus personnalisables. À adapter en fonction de vos besoins.
Enfin, nous activons le serviceGraph et nodeGraph pour avoir une vue graphique des flux de traces enrichies par les métriques. Cela nécessite l’activation de metricsGenerator pour générer les données de graphe dans prometheus.
Appliquer la config avec terraform apply. Vérifier que tout est bien déployé avec kgp -n tracing.
Collecte 📜
Bon cool, on a nos backends, mais aucun collector pour alimenter tout ça. C’est ici que Alloy entre en jeu.
Afin de distribuer au mieux la collecte des données, assez massives quand il s’agit de logs et traces, Alloy est devenu un composant de choix dans l’écosystème de l’observabilité. Il fournit une solution complète centralisée et flexible pour la collecte, le traitement et le routage des logs, métriques et traces.
L’utilisation de Prometheus Operator via les CRDs ServiceMonitor/PodMonitor (mode pull/scraping) exclu l’utilisation d’Alloy pour la collecte des métriques de l’infra, hors métriques OLTP (mode push) encore rarement utilisé. Il nous servira donc principalement pour les logs et traces. Pour la partie logs, il remplace pleinement Promtail, l’outil historique pour la collecte des logs.
resource "kubernetes_namespace_v1" "telemetry" { metadata { name = "telemetry" labels = { "pod-security.kubernetes.io/enforce" = "privileged" } }}
resource "kubernetes_config_map_v1" "alloy" { metadata { name = "alloy" namespace = kubernetes_namespace_v1.telemetry.metadata[0].name }
data = { "config.alloy" = <<EOFdiscovery.kubernetes "pod" { role = "pod"}
discovery.relabel "pod" { targets = discovery.kubernetes.pod.targets
rule { source_labels = ["__meta_kubernetes_namespace"] action = "replace" target_label = "namespace" }
rule { source_labels = ["__meta_kubernetes_pod_name"] action = "replace" target_label = "pod" }
rule { source_labels = ["__meta_kubernetes_pod_container_name"] action = "replace" target_label = "container" }
rule { source_labels = ["__meta_kubernetes_pod_label_app_kubernetes_io_name"] action = "replace" target_label = "app" }
rule { source_labels = ["__meta_kubernetes_namespace", "__meta_kubernetes_pod_container_name"] action = "replace" target_label = "job" separator = "/" replacement = "$1" }
rule { source_labels = ["__meta_kubernetes_pod_uid", "__meta_kubernetes_pod_container_name"] action = "replace" target_label = "__path__" separator = "/" replacement = "/var/log/pods/*$1/*.log" }
rule { source_labels = ["__meta_kubernetes_pod_container_id"] action = "replace" target_label = "container_runtime" regex = "^(\\S+):\\/\\/.+$" replacement = "$1" }}
local.file_match "pod" { path_targets = discovery.relabel.pod.output}
loki.source.file "pod" { targets = local.file_match.pod.targets forward_to = [loki.process.pod.receiver]}
loki.process "pod" { stage.cri {} stage.static_labels { values = { cluster = "local", } }
forward_to = [loki.write.endpoint.receiver]}
loki.write "endpoint" { endpoint { url = "http://loki-gateway.logging/loki/api/v1/push" }}
otelcol.receiver.otlp "default" { http {} grpc {}
output { metrics = [otelcol.processor.batch.default.input] traces = [otelcol.processor.batch.default.input] logs = [otelcol.processor.batch.default.input] }}
otelcol.processor.batch "default" { output { metrics = [otelcol.exporter.otlphttp.prometheus.input] logs = [otelcol.exporter.otlphttp.loki.input] traces = [otelcol.exporter.otlp.tempo.input] }}
otelcol.exporter.otlphttp "prometheus" { client { endpoint = "http://prometheus-operated.monitoring:9090/api/v1/otlp" }}
otelcol.exporter.otlphttp "loki" { client { endpoint = "http://loki-gateway.logging/otlp" }}
otelcol.exporter.otlp "tempo" { client { endpoint = "tempo.tracing:4317" tls { insecure = true } }}EOF }}
resource "helm_release" "alloy" { repository = "https://grafana.github.io/helm-charts" chart = "alloy" version = "1.8.0"
name = "alloy" namespace = kubernetes_namespace_v1.telemetry.metadata[0].name max_history = 2
set = [ { name = "serviceMonitor.enabled" value = "true" }, { name = "alloy.configMap.create" value = "false" }, { name = "alloy.configMap.name" value = kubernetes_config_map_v1.alloy.metadata[0].name }, { name = "alloy.configMap.key" value = "config.alloy" }, { name = "alloy.extraPorts[0].name" value = "otlp-http" }, { name = "alloy.extraPorts[0].port" value = "4318" }, { name = "alloy.extraPorts[0].targetPort" value = "4318" }, { name = "alloy.extraPorts[1].name" value = "otlp-grpc" }, { name = "alloy.extraPorts[1].port" value = "4317" }, { name = "alloy.extraPorts[1].targetPort" value = "4317" }, { name = "alloy.mounts.varlog" value = "true" }, { name = "controller.tolerations[0].operator" value = "Exists" }, ]}
resource "kubernetes_manifest" "traefik_ingress_route_alloy" { manifest = { apiVersion = "traefik.io/v1alpha1" kind = "IngressRoute" metadata = { name = "alloy" namespace = kubernetes_namespace_v1.telemetry.metadata[0].name } spec = { entryPoints = ["internal"] routes = [ { match = "Host(`alloy.${var.internal_domain}`)" kind = "Rule" middlewares = [ { name = "internal-basic-auth" namespace = "traefik" } ] services = [ { name = "alloy" port = "http-metrics" } ] } ] } }}Explanation
Par rapport à Promtail, il y a beaucoup plus de config à faire, prix de la flexibilité ?
Côté Helm on indique le ConfigMap à utiliser, et on expose les ports OTLP HTTP et gRPC pour activer la collecte des traces. Les applications supportant OpenTelemetry devront envoyer leurs données de spans/traces sur ces ports (ce qui est déjà le cas sur Traefik installé précédemment).
Quant aux logs, on utilise l’API Kubernetes pour aller chercher les pods et leurs containers sur lesquels Alloy devra collecter les logs, puis on applique une série de règles de relabellisation pour avoir des labels cohérents et exploitables dans Grafana.
L’exemple fourni par la doc officielle récupère le stream des logs via l’API Kubernetes. Cela a l’avantage de ne pas nécessiter de déploiement d’agent sur chaque nœud, ni d’élévation de privilège. Cependant, cela n’est pas du tout optimal en termes de charge sur l’API server ainsi que niveau réseau.
Je préfère personnellement rester sur l’approche Promtail traditionnelle de récupérer les logs directement à la source au niveau fichier brut. Dans ce mode, au niveau du chart helm, 2 éléments essentiels sont à considérer :
- On s’assure via
controller.tolerationsque les pods alloy se déploient sur l’ensemble des noeuds. Cela est nécessaire pour la collecte des logs au niveau fichier, de la même manière que pour Promtail. - On monte le volume
/var/loglocal de chaque noeud dans les pods alloy viaalloy.mounts.varlog. Ceci nécessite des privilèges élevés indiqués dans le namespace.
Il s’agit ensuite de remplacer loki.source.kubernetes par le combo local.file_match et loki.source.file, qui permette respectivement de matcher les fichiers de logs grâce à __path__ et de parser les fichiers de logs.
local.file_match "pod" { path_targets = discovery.relabel.pod.output}
loki.source.file "pod" { targets = local.file_match.pod.targets forward_to = [loki.process.pod.receiver]}En mode fichier, dans loki.process, il est important d’indiquer stage.cri afin de parser les logs au format CRI (le format standard utilisé par les runtimes de containers comme containerd ou Docker).
En résumé, côté config :
- On récupère tous les pods actifs de l’API Kubernetes.
- On applique toute une stratégie de labellisation pour avoir un truc propre à exploiter.
- On matche les fichiers de logs via
__path__pour chaque container de chaque pod puis on parse les logs au format CRI. - On précise le point d’entrée
loki-gateway.loggingde Loki pour l’écriture des logs. - On configure un récepteur OTLP par défaut pour recevoir les données OpenTelemetry. Sur ce récepteur, nous utilisons trois processeurs batch distincts pour les métriques, les traces et les logs :
- Pour la partie metrics, on forwarde vers l’endpoint OTLP de prometheus préalablement configuré au chapitre précédent
http://prometheus-operated.monitoring:9090/api/v1/otlp. - Pour la partie logs, on forwarde vers l’URL loki
http://loki-gateway.logging/otlp. - Pour la partie traces, on forwarde vers le backend Tempo sur l’endpoint
tempo.tracing:4317(format gRPC).
- Pour la partie metrics, on forwarde vers l’endpoint OTLP de prometheus préalablement configuré au chapitre précédent
L’intérêt principal d’OTLP est leur enrichissement mutuel entre métriques, logs et traces, permettant une corrélation parfaite. Ce format est en revanche spécifique par application les supportant, vu qu’il s’agit d’un nouveau protocole en mode push. Il nous servira notamment pour OpenTelemetry plus tard.
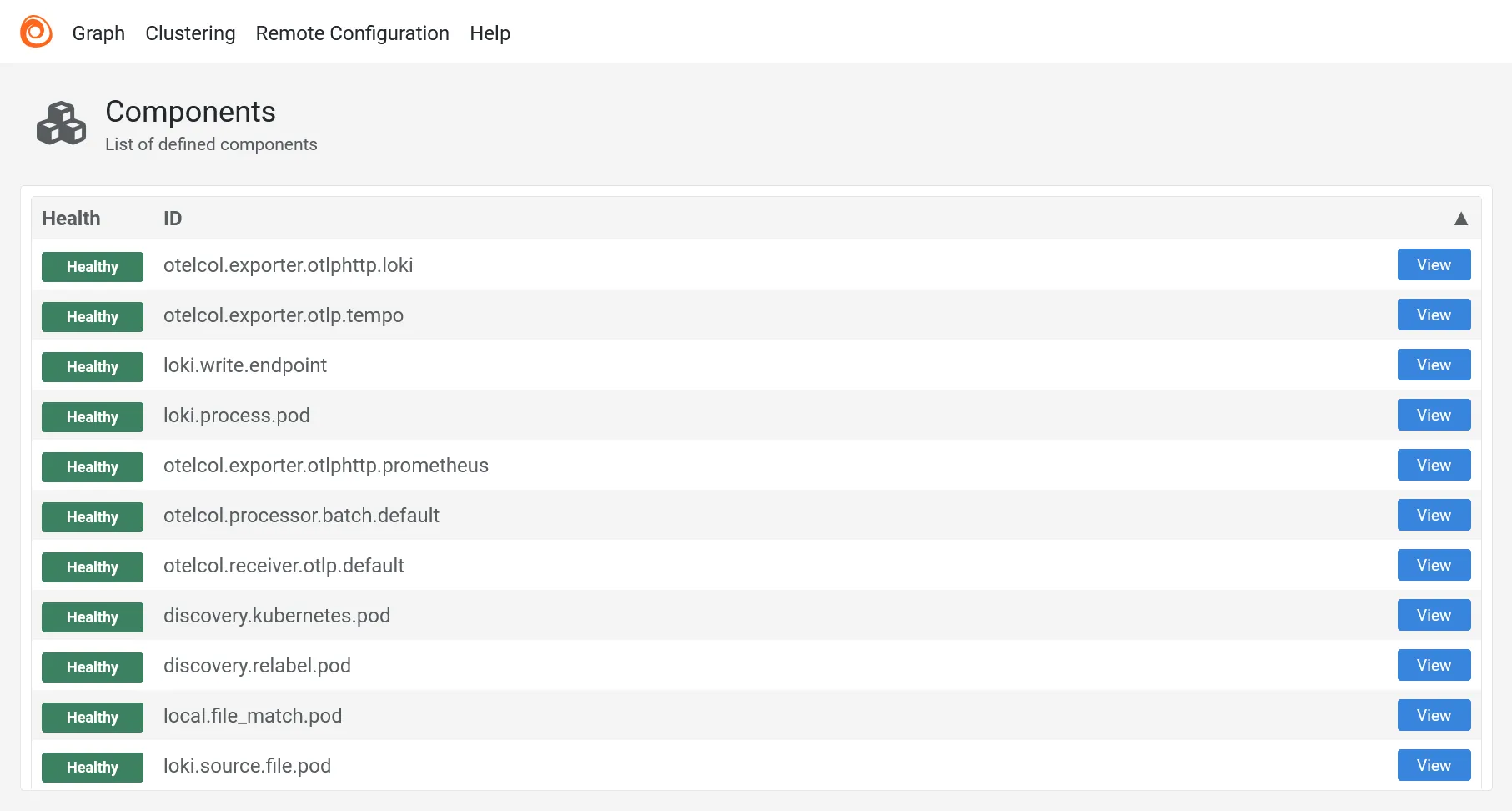
Plus qu’à terraform apply pour déployer Alloy. Vérifer avec kgp -n telemetry que tout est bien déployé. Puis allez faire un tour sur https://alloy.dev.ohmytalos.io pour vérifier l’état des composants de collecte.
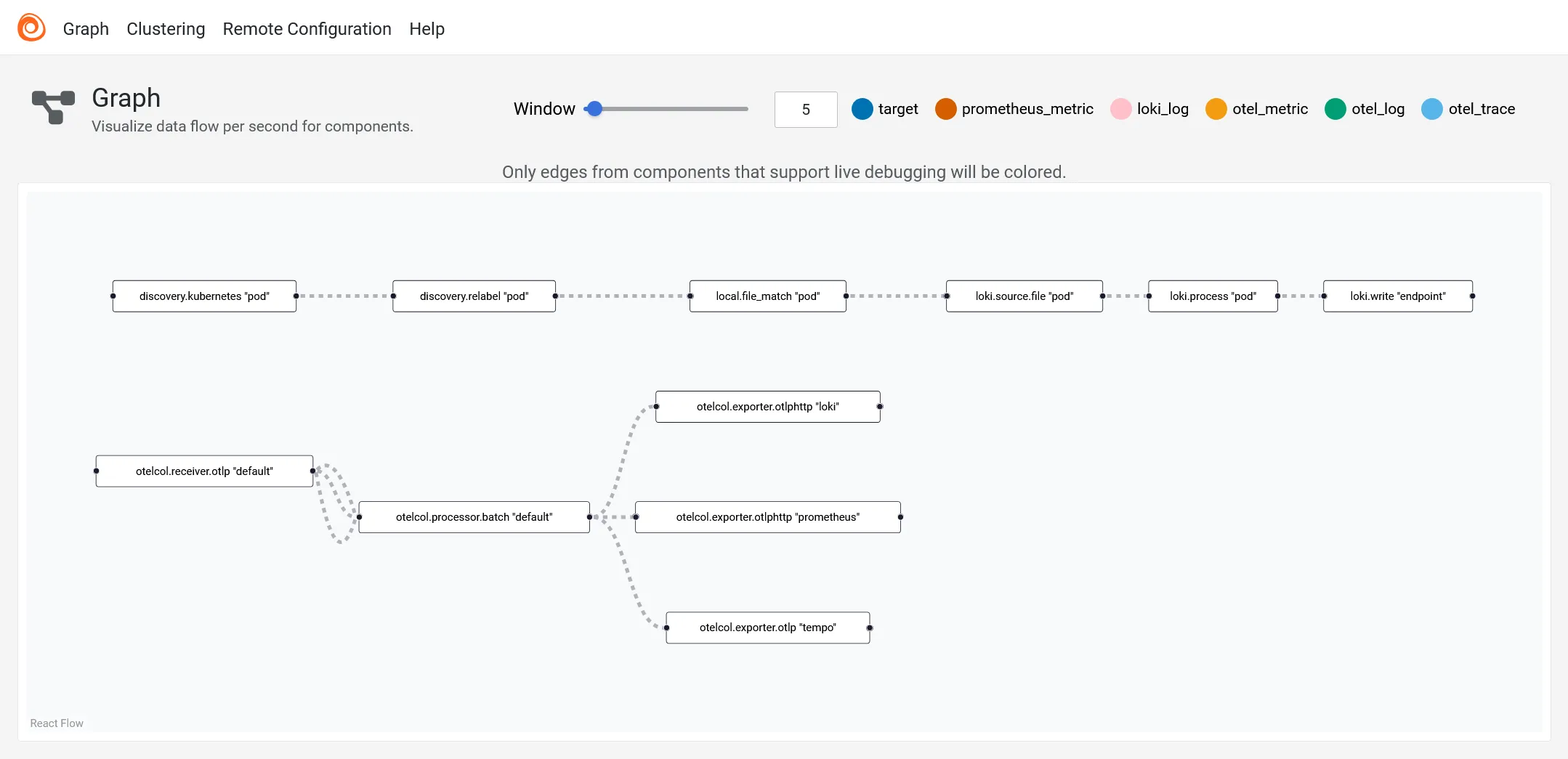
Alloy fourni également un graphe de flux des données collectées.
Et voilà les logs devraient commencer à arriver dans loki très rapidement. Traefik étant déjà configuré à la section des ingress pour envoyer les traces, vous devriez aussi voir les premières traces arriver dans Tempo.
Visualisation des logs
Pour visualiser tout ça, allez dans la section Drilldown de Grafana, section logs pour avoir un aperçu rapide des logs des principaux composants.
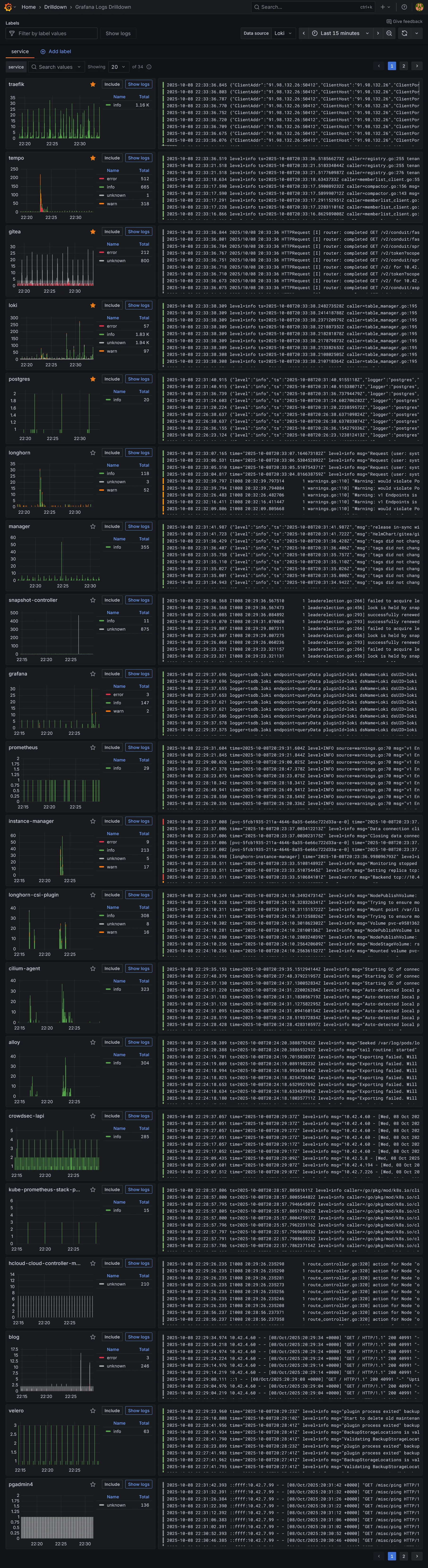
Naviguer dans les logs de Traefik :
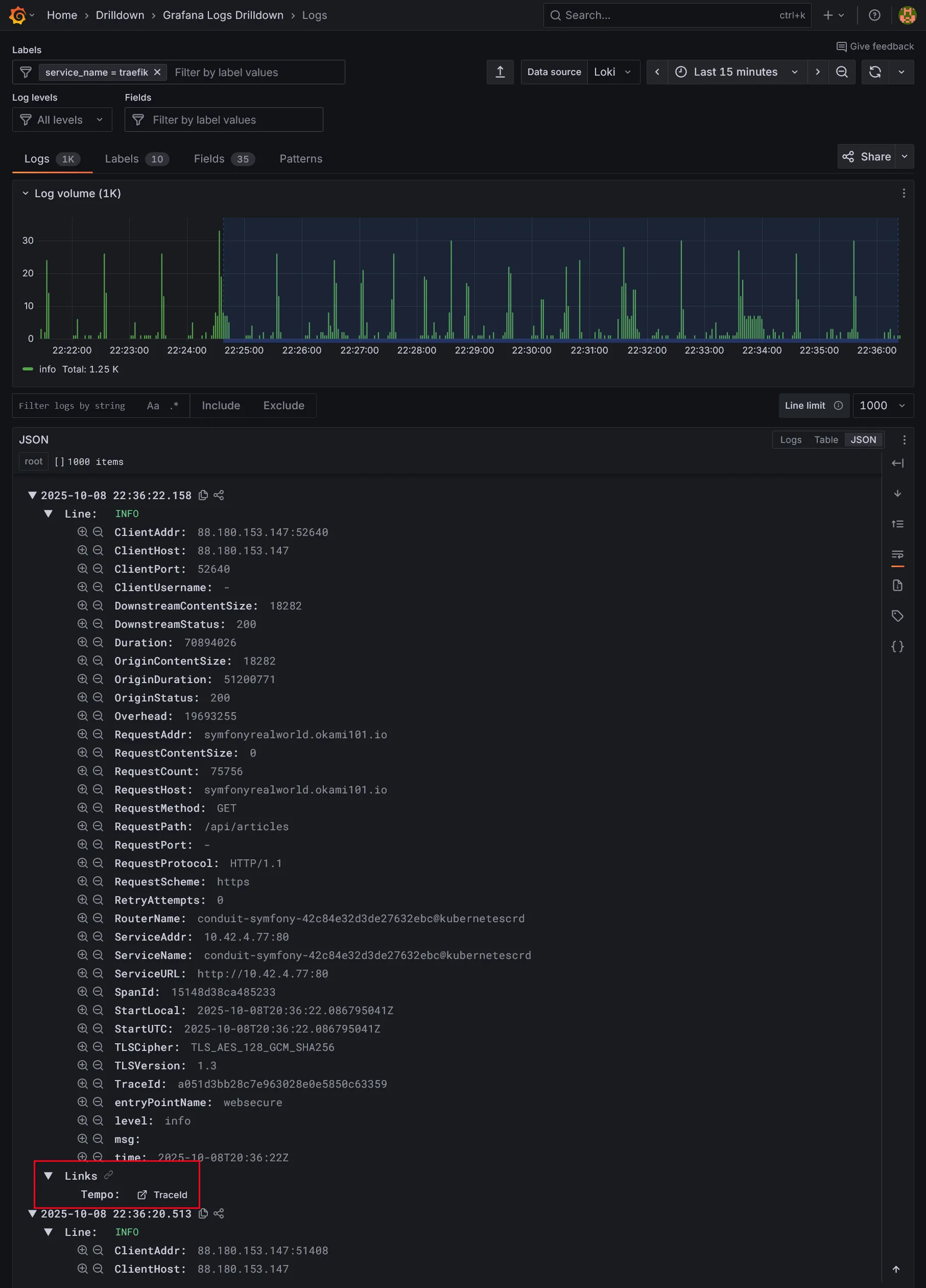
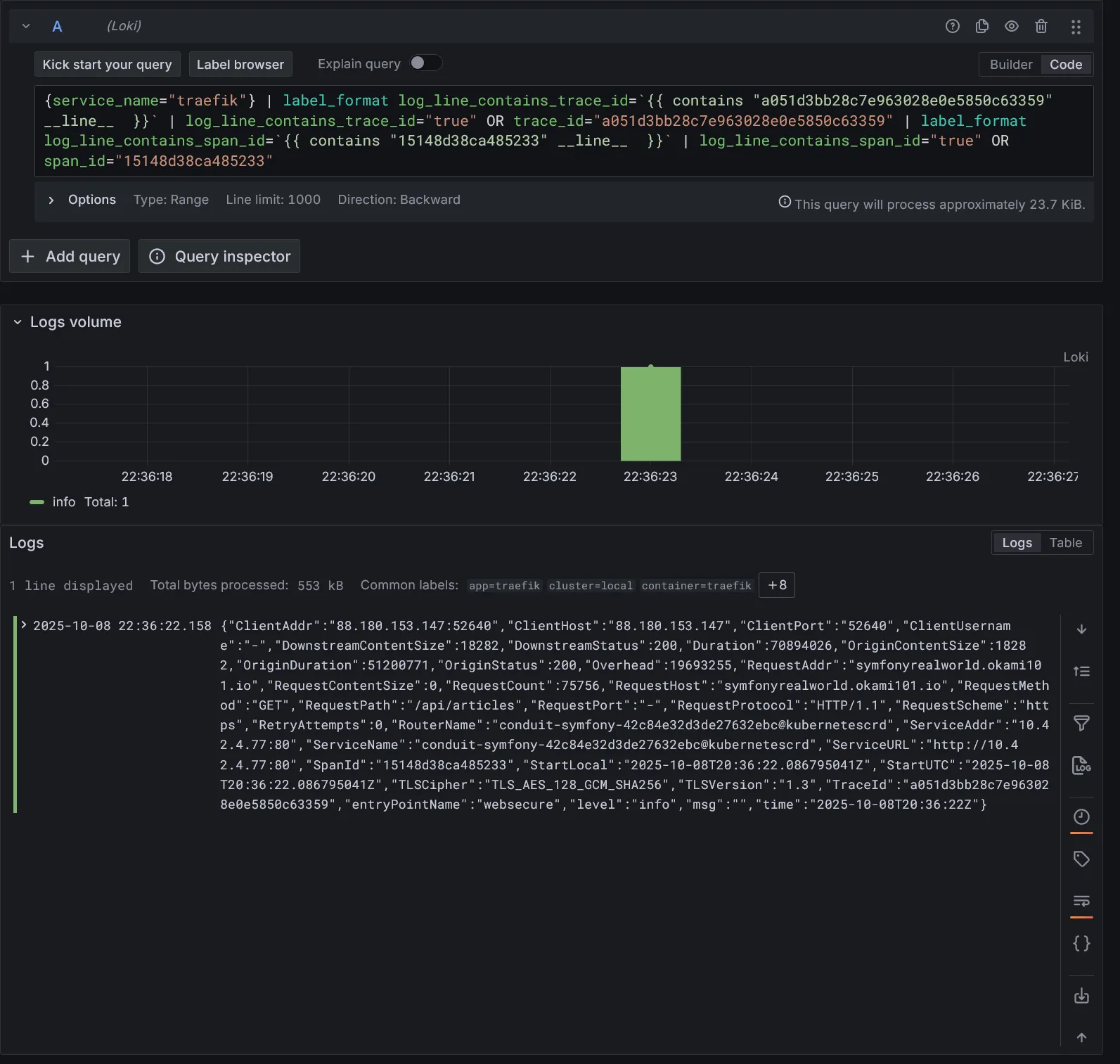
Grâce au derivedField configuré dans le datasource Loki, vous pouvez cliquer sur le TraceId dans les logs pour accéder directement à la trace correspondante dans Tempo.
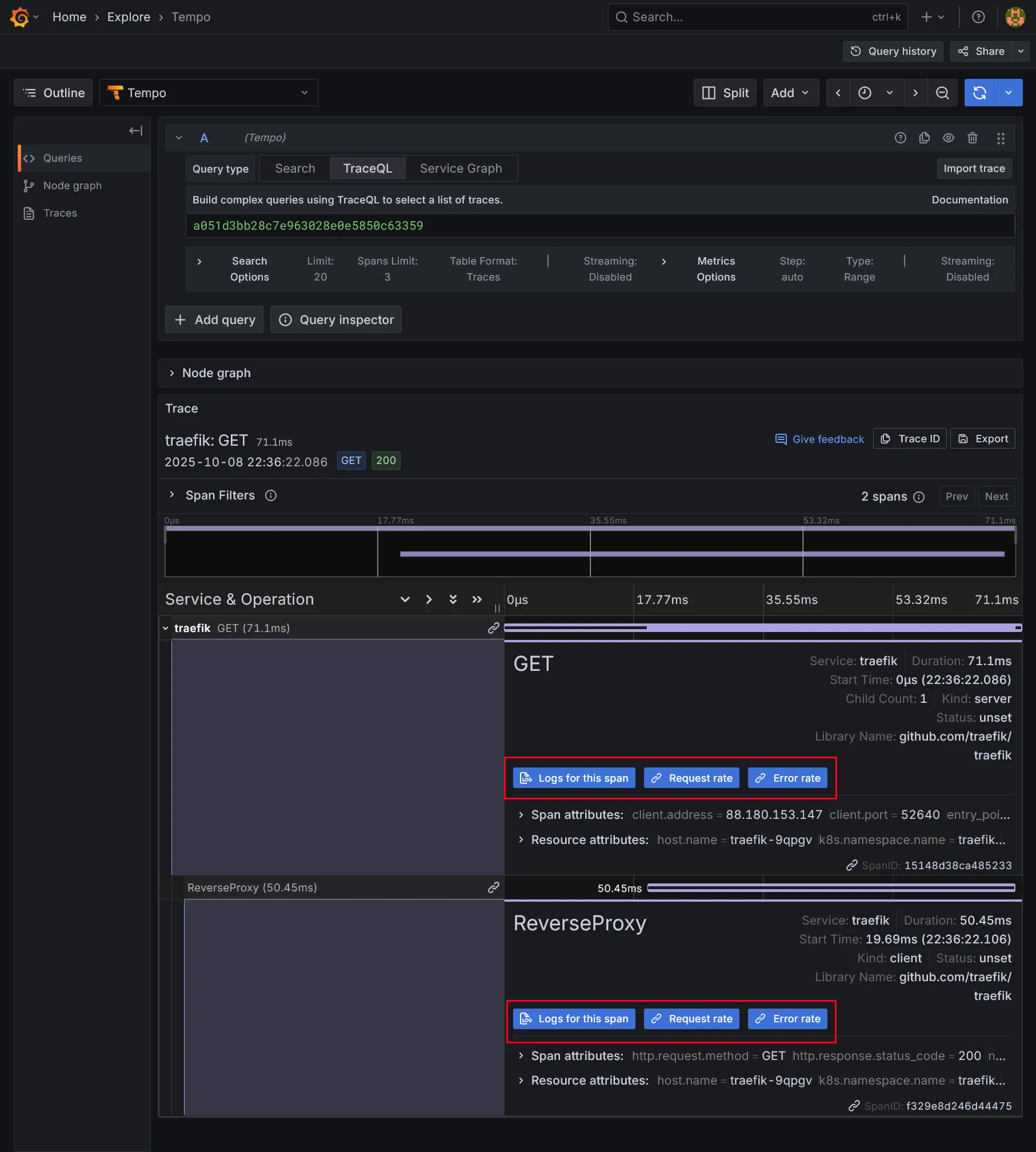
En dépliant les spans, vous y retrouverez les fameux liens créés dans la datasource de tempo, via les paramètres tracesToLogsV2 et tracesToMetrics.
Corrélation des logs sur le span sélectionné :
Corrélation des métriques personnalisées sur le span sélectionné :
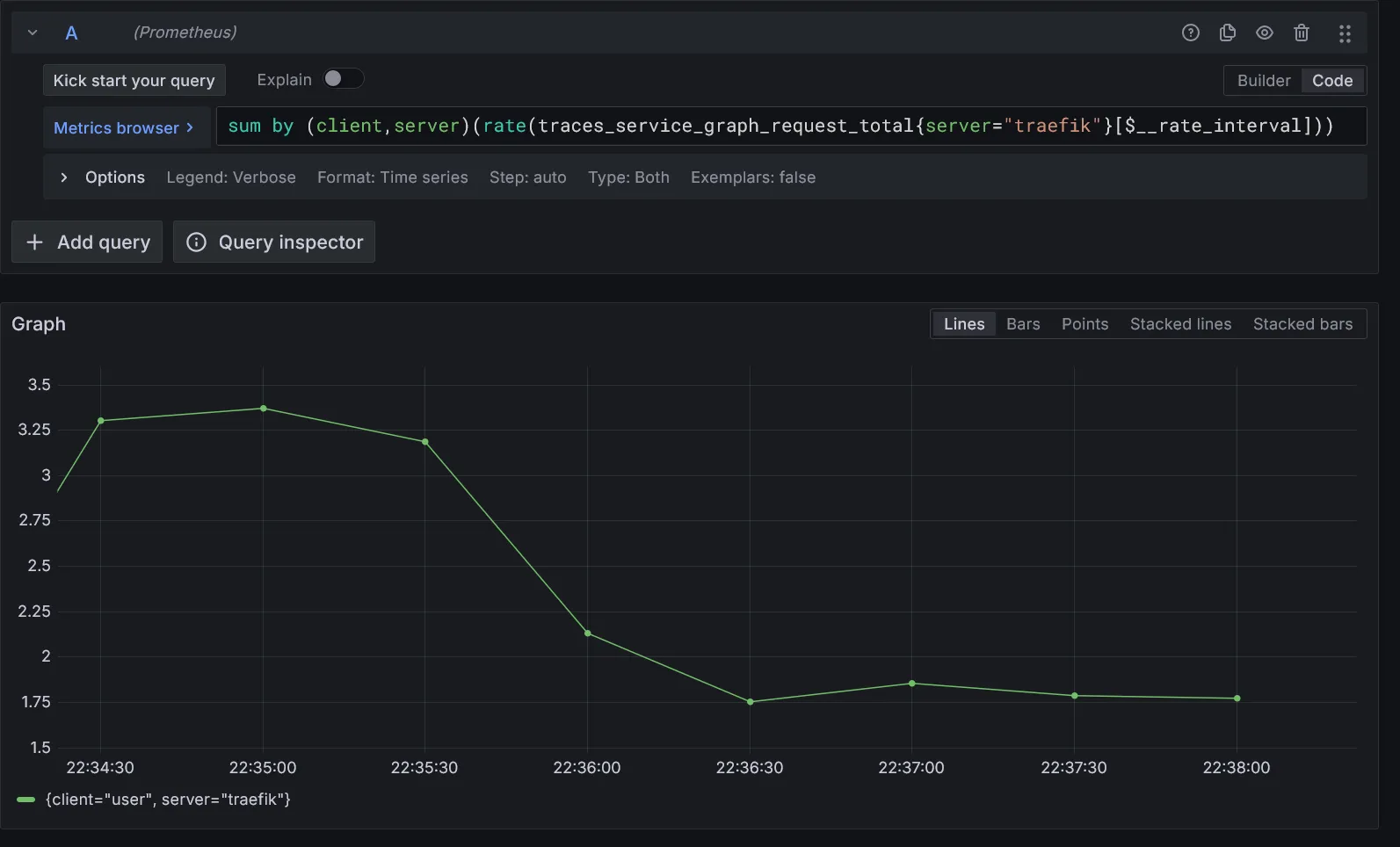
Vous pouvez créer autant de métriques personalisées que vous souhaitez. Il vous suffira de les ajouter dans la section queries du paramètre tracesToMetrics du datasource Tempo.
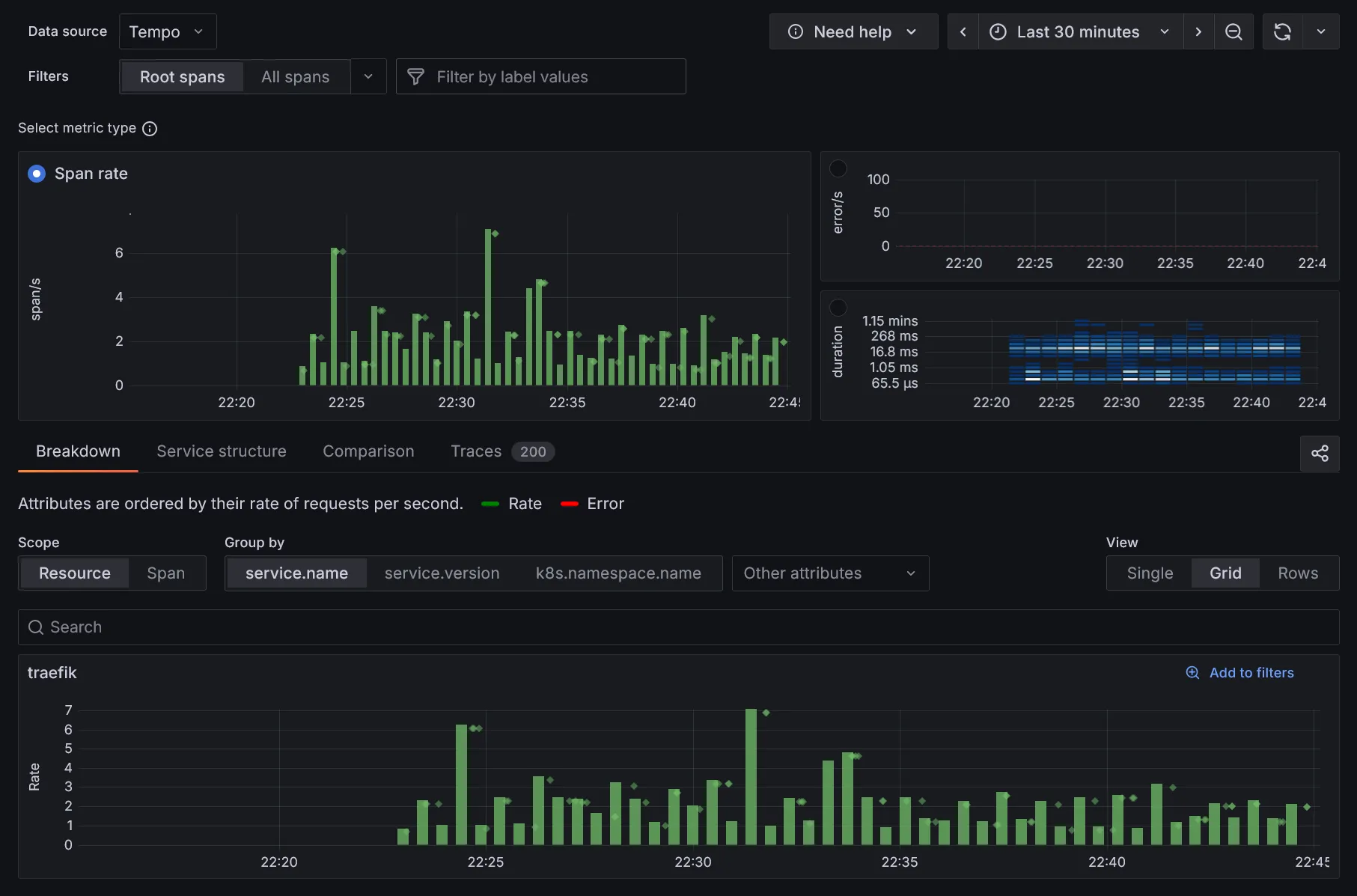
Visualisation des traces
Grafana fourni également une vue complète des traces :
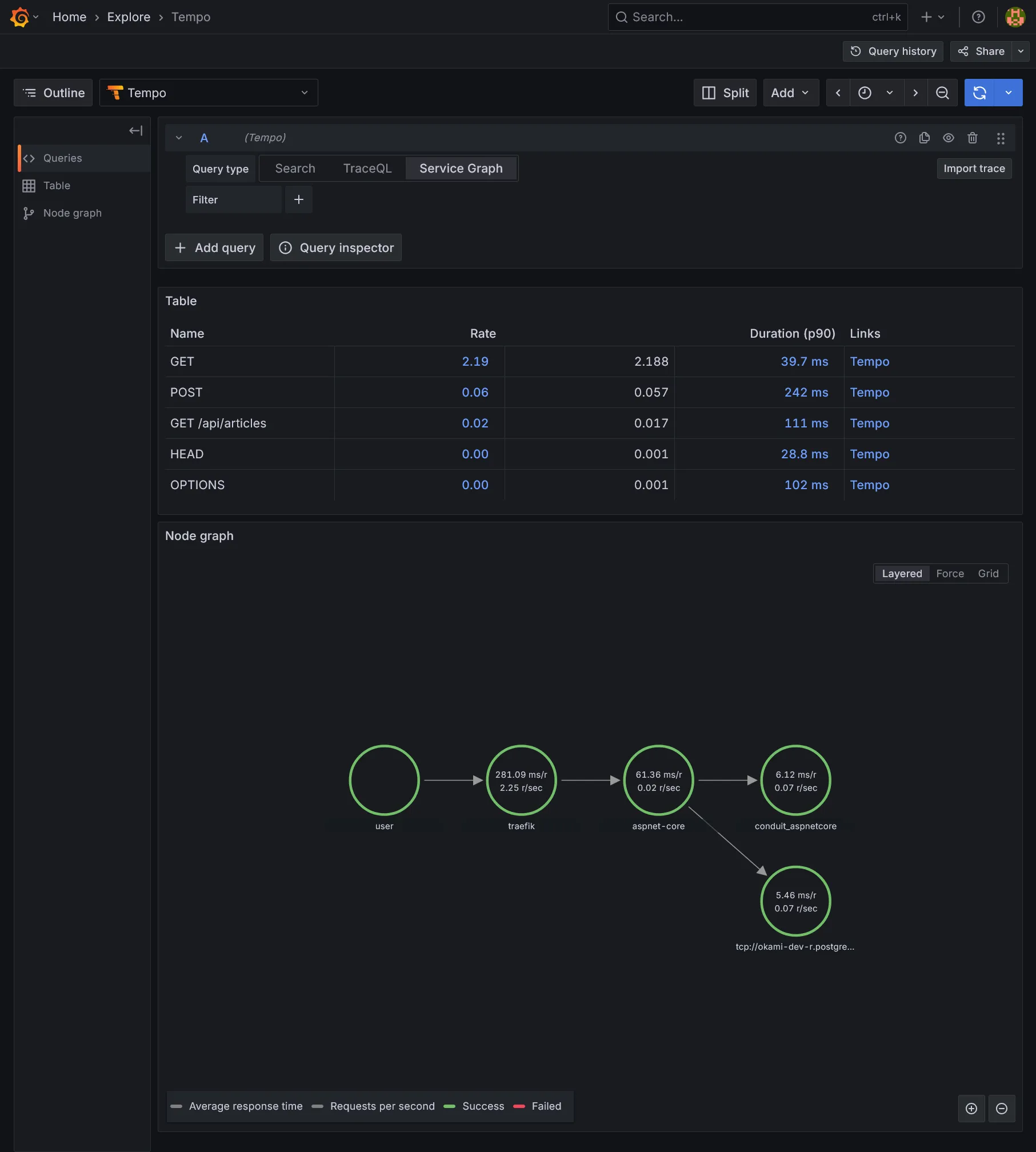
Une vue par graphe des flux de services est aussi disponible, enrichie par les métriques personnalisées issues des traces :
Conclusion
On est bon pour la mise en place des collecteurs et agrégateurs de logs et traces. Nous verrons plus tard au travers d’une application réelle comment l’intégrer à travers ces outils. Il est temps d’installer fluxcd pour le déploiement automatique de nos applications, c’est parti.